Tanto en plataformas de redes sociales como en las tendencia de Google, de los aspirantes de MORENA, Sheinbaum y Ebrard son los que destacan
A una semana de actividad política de los aspirantes a la candidatura de la 4T, las tendencias sociodigitales dan ventaja a Claudia Sheinbaum en una carrera cerrada a solo dos competidores
Antony Flores Mérida
Las interacciones en espacios sociodigitales dan pistas que nos ayudan a interpretar la forma en que se desenvuelven determinados acontecimientos (culturales, sociales, políticos…). En este sitio se han realizado exploraciones a la discusión digital en temas como la revocación de mandato o la emergencia por COVID-19 en Twitter. Uno de los temas del momento es el proceso de selección de las candidaturas presidenciales rumbo a la elección de 2024 y en los distintos espacios sociodigitales, la selección de la candidatura de MORENA (y la 4T) ocupa los primeros lugares en la conversación.
Una pequeña muestra de videos de la red social que utilizan la palabra “corcholatas” permitió obtener datos de 440 publicaciones a las cuales se le extrajeron las etiquetas (hashtags) utilizados. La exploración se puede apreciar en la nube de palabras que se ofrece a continuación.
Los datos de esa pequeña muestra dan cuenta de cómo las etiquetas referentes a la ex Jefa de Gobierno de la ciudad de México, Claudia Sheinbaum y las del ex titular de la SRE, Marcelo Ebrard, son las más presentes en los 440 videos obtenidos en la búsqueda. No debemos pasar por alto que distintas etiquetas referentes al presidente se encuentran con una gran frecuencia en esta plataforma (AMLO, 4T, Amlovers, CorcholatasDeAMLO, LopezObrador, entre otras).
Nube de palabras elaborada a partir de las etiquetas presentes en 440 videos de la red social Tik Tok que mencionan la palabra «corcholadas».
Entre los aspirantes, el ex titular de SEGOB, Adán Augusto López, aparece en tercer lugar en menciones (aunque por cada tres menciones de Sheinbaum o Ebrard hay una de Adán Augusto). Los aspirantes Gerardo Fernández Noroña y Ricardo Monreal tienen casi el mismo nivel de menciones mientras que el aspirante del Partido Verde, Manuel Velasco, solo aparece en tres menciones en esta muestra de datos.
¿Esta tendencia está presente en otros espacios de conversación? ¿Qué nos dicen estos patrones de la contienda interna en MORENA para definir su candidatura presidencial? Para tratar de ensayar respuestas a estas cuestiones se presentan, de forma exploratoria, algunos datos de las plataformas Twitter y Google Trends.
La relación entre procesos electorales y tendencias sociodigitales
El uso de técnicas de big data como predictor de comportamientos políticos ha estado presente desde hace algunos años en el análisis de la ciencia política. Un trabajo de Prado-Román y otros (2021) cita, entre otras investigaciones, la de Christine Ma-Kellams et al. (2017) sobre el uso de Google Trends como predictor de resultados electorales. Prado-Román y sus compañeros asumen que el número de términos de búsqueda utilizados por los usuarios de plataformas sociodigitales pueden dar cuenta de la forma actual y futura de pensar y actuar de sectores importantes de la población (2021, p. 3).
Los autores del estudio citado plantean, sin embargo, una caución, y es que este tipo de «predictores» sólo funcionan en procesos democráticos y en territorios donde no hay restricciones para el uso de tecnologías digitales de comunicación interactiva. Aunque los autores ponen a prueba sus hipótesis en los casos de elecciones de Estados Unidos y Canadá, este bien podría aplicarse al contexto mexicano.
Sin embargo, no nos encontramos ante una elección presidencial sino ante el proceso interno de un grupo de partidos para elegir a la persona que, eventualmente, será su candidato/a presidencial. Por ello, más que un predictor, para esta exploración los datos pueden bien dar cuenta del ‘estado de la conversación sociodigital’ pues, a final de cuentas (y pese a que el proceso de MORENA contempla una encuesta), no estamos ante un proceso electivo convencional.
La conversación en Twitter
Durante la primera semana de actividad de las personas que buscan encabezar los “comités de defensa de la 4T” (término usado por MORENA y sus partidos aliados para quien, presumiblemente, será la persona que ostentará la candidatura presidencial), se recogieron 1.1 millones de publicaciones que mencionan los nombres o usuarios de Twitter de los cinco principales contendientes. Aunque la exploración a profundidad no se presenta en esta ocasión, sí una breve visualización de 75 mil publicaciones únicas emitidas durante los días sábado y domingo al concluir su primera semana de actividades.
Al igual que ocurre en la pequeña muestra de datos de Tik Tok, en Twitter el patrón emerge de nuevo: la aspirante Claudia Sheinbaum es la más mencionada en esta muestra de datos (casi 35 mil ocasiones, es decir, prácticamente la mitad de los datos presentes) mientras que Marcelo Ebrard tiene un 50% menos menciones que la ex Jefa de Gobierno (17.2 mil). En esta red social, Adán Augusto está más cerca del ex canciller de lo que ocurrió en Tik Tok con unas 16 mil menciones. El resto de aspirantes se encuentra, sin embargo, más lejos: Fernández Noroña logra unas 3 mil 500 y Ricardo Monreal unas 3 mil 200.
Nube de palabras elaborada a partir de una muestra de 75 mil publicaciones en Twitter que mencionan a alguno de los aspirantes a la candidatura presidencial de MORENA.
En esta muestra de datos (y a expensas de explorar la serie que abarca toda la semana), Claudia Sheinbaum es más mencionada en la plataforma Twitter superando por mucho a cualquiera de sus compañeros contendientes. Ebrard y Adán Augusto tienen una cantidad muy similar de menciones mientras que Noroña y Monreal, con cantidades muy parecidas, están muy lejos en la carrera de las menciones en Twitter.
Google Trends: una carrera presidencial entre dos aspirantes
La carrera por la candidatura de la 4T para el proceso de 2024 está, como se puede ver, muy marcada en distintas plataformas. En Google parece ocurrir algo muy similar.
Los servicios de Alphabet permiten a las personas usuarias buscar información, noticias, imágenes, videos… en toda la web. Google es uno de los servicios más usados por los mexicanos –de hecho, nuestro país es uno de los 10 que más usan los servicios de la empresa– y por ello, las tendencias de búsqueda en este servicio son un punto a considerar.
Para este ejercicio realizamos, en un navegador (Safari) y con opciones de anonimización (sin registro en cuenta de Google y con navegación privada) una consulta a Google Trends en la que colocamos los nombres de los cinco aspirantes principales a la candidatura de MORENA y sus partidos aliados.
Al colocar los nombres, en lugar de referirlos como “Tema” se eligió la opción de “Término de búsqueda” para todos los casos, para tratar de simular la conducta natural de un usuario promedio. La exploración contempla las mediciones para los últimos 30 días (con corte al 29 de junio de 2023) y se ha elegido la “Búsqueda web” como parámetro (en lugar de Noticias o cualquier otra opción).
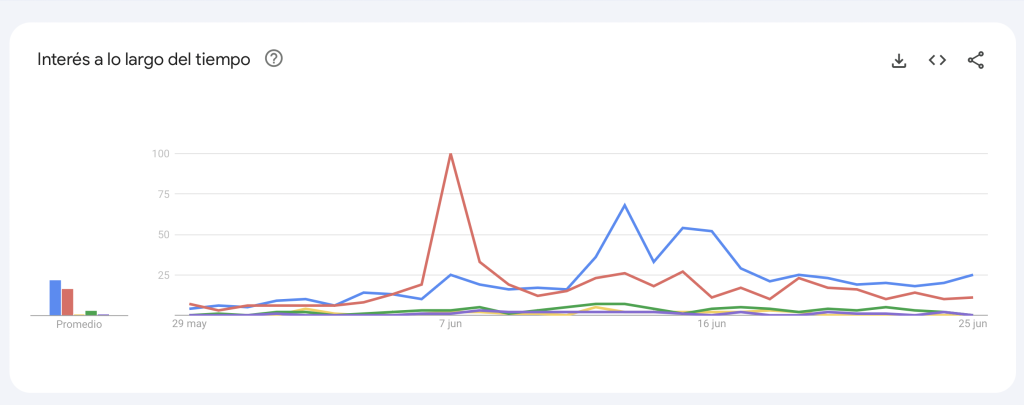
La primera gráfica muestra el “Interés a lo largo del tiempo” para el periodo seleccionado. El color azul representa a Claudia Sheinbaum, el rojo a Marcelo Ebrard, el amarillo a Adán Augusto López, el verde a Ricardo Monreal y el violeta a Fernández Noroña.
Gráfico de interés a lo largo del tiempo. Elaborado mediante Google Trends.
Al igual que ocurre en plataformas de red social, Sheinbaum parece contar con la mayor atención por parte de los usuarios y la comparte con Marcelo Ebrard.Los momentos de mayor volumen de búsquedas para cada uno coinciden (como cabe esperar) con eventos altamente mediatizados. La fecha con mayor número de búsquedas sobre la ex Jefa de Gobierno es el 13 de junio (en una tendencia que inicia varios días antes) un día después de que anunciara que pediría licencia a su cargo el 16 de junio días en los que ocupa los volúmenes más altos de búsquedas en Google. De hecho, las palabras relacionadas a su renuncia son las que ocupan los primeros lugares.
Por su parte, Marcelo Ebrard tuvo el volumen más alto de búsquedas el 7 de junio después de que anunciara que sería el primero de los aspirantes a la candidatura de la 4T en dejar su cargo y aunque mantuvo la atención de los usuarios por un par de días, el volumen de búsquedas relacionadas al ex canciller ha ido en descenso y se mantiene por debajo de las búsquedas sobre Sheinbaum Pardo. Al final del periodo observado, Claudia Sheinbaum mantiene un nivel de interés de 25 mientras que Ebrard se coloca en 11 (valores relativos a 100, el momento máximo para todo el periodo).
El resto de los aspirantes han tenido volúmenes de búsqueda muy por debajo de estos dos punteros y solo Ricardo Monreal ha llegado a niveles de atención (un máximo de 7 sobre 100) en algunos de los días previos al inicio de las giras de los aspirantes, el 19 de junio.
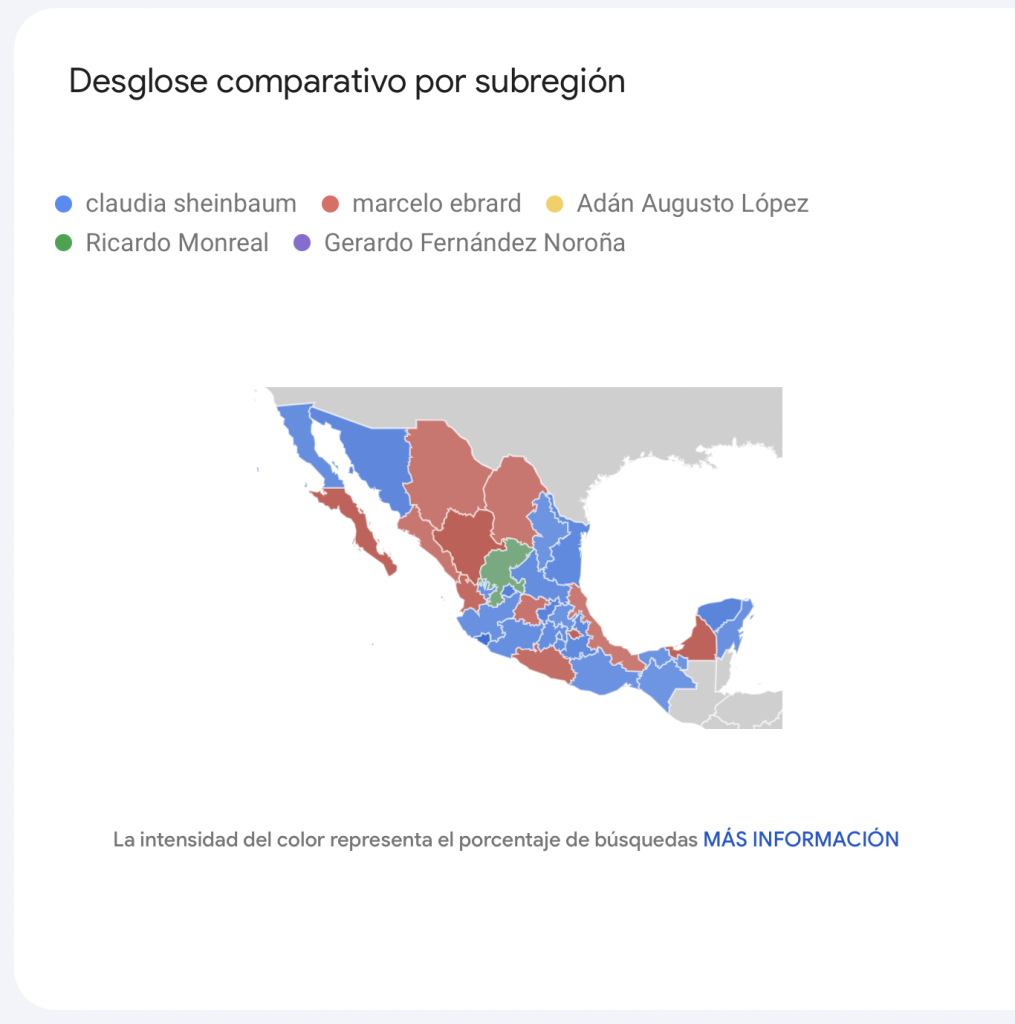
La forma en que la atención de los usuarios de Google se distribuye en el territorio también puede ser llamativa. El mapa muestra el color correspondiente a cada aspirante que se ubicó con el primer lugar en volumen de búsquedas para el periodo observado.
Comparación de las búsquedas en Google en distintas regiones del país. Elaborado con Google Trends.
Sheinbaum destaca en estados como Colima, Aguascalientes, Querétaro, Yucatán y Sonora con los niveles de atención de los buscadores más altos; Ebrard por su parte aparece con mayor presencia en búsquedas desde Durango, Tlaxcala, Campeche, Baja California Sur y Nayarit. Para la primera, la atención ha ido en aumento en Sonora pero también en Sinaloa, mientras que en el caso de Ebrard, la atención ha empezado a subir en estados del sur como Oaxaca y Guerrero, así como en algunas zonas del centro como el Estado de México.
En cuanto a Adán Augusto López, las búsquedas sobre el ex gobernador de Tabasco solo han tenido cierta densidad (aunque sin llegar a primeros lugares) en zonas del sur como Chiapas, Guerrero y Yucatán. Ricardo Monreal obtiene el primer lugar en interés en Zacatecas (de donde es originario y que gobernó de 1998 a 2004) mientras que Fernández Noroña, que no destaca en ningún estado, mantiene cierto interés en Hidalgo.
De las tendencias a los eventos políticos
¿Son las conductas de personas usuarias de las plataformas un indicador de preferencias electorales? ¿Son estas tendencias resultado o causa de la forma particular en que ciertos mensajes políticos se mediatizan? Si se han de seguir los supuestos de Prado-Román et al. (2021) y otros estudios que afirman la relación que existe entre conductas de búsqueda en línea y resultados electorales, se podría afirmar, por ejemplo, que la atención que Claudia Sheinbaum mantiene en redes como Twitter y Tik Tok así como los datos sobre búsquedas en Google permiten anticipar que esta se colocará en las preferencias de las encuestas que realizará MORENA y será, eventualmente, la candidata a la presidencia del proyecto político de la 4T.
Tan solo en el caso de Google Trends, el volumen promedio de la atención hacia Sheinbaum Pardo es cinco puntos mayor que la que se da a Marcelo Ebrard (22 vs. 17, promedio para todo el periodo). Sin embargo, en algunos periodos la diferencia entre ambos se cierra por lo que son los eventos de las giras (o campañas) de los aspirantes los que habrán de dar forma a estas tendencias.
Lo que parece más claro es que la competencia interna de MORENA se definirá entre estos dos personajes pues el resto (incluido el ex titular de SEGOB, Adán Augusto López) no cuentan con suficiente atención por parte de los usuarios en términos generales y solo logran cierta tracción en algunos estados, aunque siempre la comparten con los dos punteros.
Luego de una semana de activismo electoral, las tendencias pues, parecen definidas hacia dos aspirantes. Aunque aún falta tiempo de giras de los aspirantes (o asambleas, como las define MORENA) hasta finales de agosto y la encuesta no se realizará sino en los días posteriores a esta actividad, si alguna sorpresa depara el proceso interno de la 4T, ésta no debería tardar en presentarse.
REFERENCIAS
Ma-Kellams, Christine & Bishop, Brianna & Zhang, Mei & Villagrana, Brian. (2017). Using “Big Data” Versus Alternative Measures of Aggregate Data to Predict the U.S. 2016 Presidential Election. Psychological Reports. 121. 003329411773631. 10.1177/0033294117736318.
Prado-Román, C., Gómez-Martínez, R., & Orden-Cruz, C. (2021). Google Trends as a Predictor of Presidential Elections: The United States Versus Canada. American Behavioral Scientist, 65(4), 666-680. https://doi.org/10.1177/0002764220975067
Ariadna Fernanda López tenía 27 años. El 30 de octubre pasado, después de acudir a una reunión con amigos, desapareció y fue encontrada dos días más tarde junto a una carretera en el municipio de Tepoztlán, en Morelos. Familiares y amigos habían empezado a buscarla y su imagen pobló las redes sociodigitales. Al saberse de su muerte, emergió el reclamo: #JusticiaParaAri.
El hashtag es uno más en la interminable bitácora digital de la violencia feminicida en México. Tan solo de enero a octubre de 2022, CIMAC documentó más de 2 mil 500 asesinatos de mujeres, de los cuales, 600 calificaron como feminicidio. La estremecedora cifra no está lejos de alcanzar o incluso superar los 977 feminicidios documentados por las autoridades en el año 2021.
Tras su desaparición y muerte, las investigaciones para esclarecer la muerte de Ariadna Fernanda han dado varios giros. La Fiscalía de Morelos afirmó dos días después de que se hallara su cuerpo que la joven había fallecido por broncoaspiración, sin embargo, la Fiscalía de la Ciudad de México rechazó esos resultados y acusó al fiscal de Morelos, Uriel Carmona, de una operación de encubrimiento del feminicidio de Ariadna Fernanda. La fiscalía capitalina informó sobre una segunda necropsia realizada a la joven que determinó su fallecimiento a causa de golpes y posteriormente, se dieron a conocer videos que muestran a una persona trasladando el cuerpo sin vida de la joven desde un departamento en la Ciudad de México y con destino desconocido. El sujeto, Rautel “N”, fue señalado como posible autor material del feminicidio en complicidad con su pareja, Vanessa “N”, quienes en primeras declaraciones habrían señalado que Ariadna abordó un taxi. Luego se sabría que se coordinaron para despistar a las autoridades.
Las investigaciones, las declaraciones de implicados y la confrontación más política que judicial entre las autoridades de CDMX y la Fiscalía de Morelos, han enmarcado el feminicidio de Ariadna Fernanda pero, con ello, desdibujado el reclamo de justicia de familiares y amistades de la víctima, así como de una ciudadanía indignada por la violencia feminicida en nuestro país.
Para explorar la discusión y tratar de encontrar la dimensión del reclamo, exploramos la conversación en Twitter que durante los últimos días ha girado en torno a la joven Ariadna Fernanda López.
La mediatización de la tragedia: olas de discusión y el reclamo #JusticiaParaAri
La discusión en torno al feminicidio de Ariadna Fernanda parece haber seguido el ritmo de los flujos informativos en torno a las investigaciones judiciales. Esto, antes que permitir mayor densidad al reclamo de #JusticiaParaAri parece mantenerlo en un segundo plano, manteniendo las confrontaciones entre autoridades en primer nivel de la discusión.
Para tratar de describir estos ritmos de discusión se descargaron 85,903 publicaciones de Twitter que respondían a los siguientes términos: “caso ariadna”, “rautel n”, #JusticiaParaAri, #AriadnaFernanda. El objetivo detrás de esta estrategia de búsqued fue tratar de captar todas las discusiones relacionadas al feminicidio de Ariadna Fernanda. En lugar de limitar la descarga a un solo término o conjunto de palabras, buscamos aquellas que aparecían más frecuentemente en torno a este evento y las concentramos en una sola llamada a la API de Twitter.
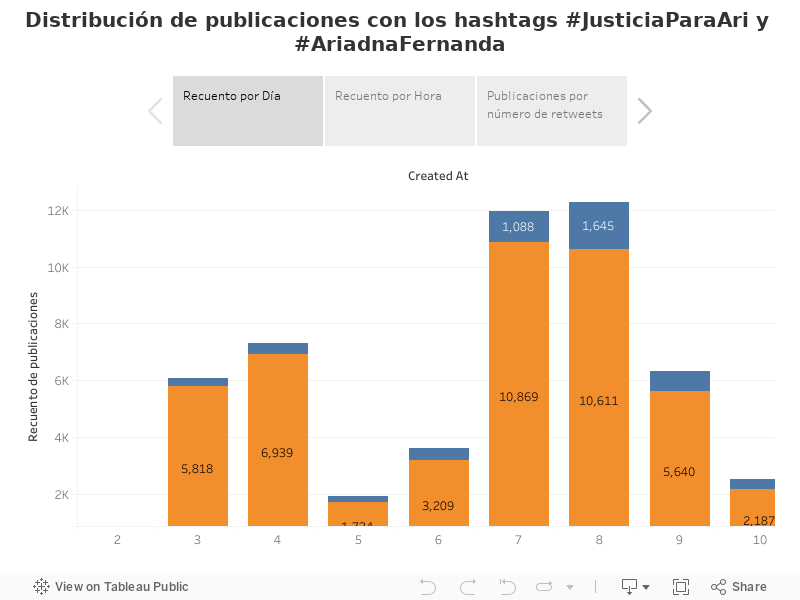
La siguiente gráfica muestra la distribución de las publicaciones que conforman la muestra. Se distinguen los tuits originales (azul) de los retuits (naranja). Debido a la ventana que ofrece la API de Twitter, la llamada hecha el 10 de noviembre permitió recuperar solo tuits desde el 3 de noviembre, un día después del hallazgo del cuerpo de Ariadna Fernanda.
Si bien, las publicaciones de reclamo con #JusticiaParaAri estuvieron presentes desde el 3 de noviembre, es a partir del lunes 7 cuando la discusión empieza a aumentar en la plataforma. Ese día, las declaraciones de las autoridades de CDMX confrontando a la Fiscalía de Morelos empiezan a poblar los medios, a su vez, se dicta prisión preventiva a Vanessa “N”, implicada en el feminicidio, se revelan imágenes de Rautel “N” trasladando el cuerpo de Ariadna y, el mismo sujeto implicado se entrega a las autoridades en el estado de Nuevo León.
EL martes 8 de noviembre, el feminicidio de Ariadna es el objeto de la confrontación entre el fiscal de Morelos, Uriel Carmona, y la jefa de Gobierno de la Ciudad de México, Claudia Sheinbaum, entre quienes se intercambian acusaciones. Y aunque Rautiel “N” y Vanessa “N” ya se encontraban en prisión y próximos a enfrentar proceso, la discusión mediática poco o nada tenía que ver con el fenómeno de la violencia feminicida y la necesidad de procurar justicia a Ariadna Fernanda y más con la confrontación entre autoridades.
Cuando vemos la forma en que se desenvolvió la conversación (Gráfico 2), se ve cómo la mayor intensidad se encuentra entre las últimas horas del domingo 6 y primeras del miércoles 9 de noviembre.
Gráfico 2
Mediáticamente, es la discusión política la que mantiene la relevancia del tema. Para revelar la capa de reclamo de justicia, se descargaron exclusivamente las publicaciones con las etiquetas #JusticiaParaAri y #AriadnaFernanda y el patrón de publicaciones es similar. De hecho, si se compara la descarga global con la sub-muestra, se puede notar que esta última representa más de la mitad de la primera. La segunda descarga nos ofreció 52,467 publicaciones en el mismo periodo y su comportamiento se puede notar en el siguiente gráfico interactivo.
Los días 7 y 8 de noviembre son los más activos con más de mil y mil 600 tuits originales, respectivamente, usando los hashtags, que generaron a su vez más de 10 mil republicaciones en cada jornada.
Es decir, el reclamo de #JusticiaParaAri no solo está presente en la discusión sino que parece el más denso de la misma. ¿Por qué la representación mediática de este feminicidio parece entonces tan centrada en la confrontación entre autoridades?
En la Nube de Emojis que se presenta a continuación se encuentran los 300 marcadores gráficos presentes en los mensajes de la muestra principal con que se elaboró esta entrada. Como se puede ver, son marcadores de alerta y de medios (🚨 🔴 📺 📰 👇 📻) los que alcanzan una mayor frecuencia.
Nube de Emojis
Sin embargo, también hay marcadores afectivos que están presentes, los que manifiestan rabia y molestia (😡 🤬), tristeza y dolor (😭 😢 😓 😞 💔), el corazón violeta del activismo digital feminista ( 💜 ) y, de forma difícil de entender, el emoji de burla ( 😂 ) que parece poner de manifiesto la presencia de discusiones que banalizan o que usan el evento para confrontar a sus adversarios políticos.
Es decir, si bien en términos de presencia y densidad, el reclamo #JusticiaParaAri está presente en los datos analizados, y parte de ello se manifiesta en marcadores gráfico-emocionales de rabia, tristeza y movilización, la mayor preponderancia parecen obtenerla las representaciones mediáticas del caso que, habida cuenta la cobertura, han tendido a centrarse en la confrontación entre autoridades de Morelos y Ciudad de México.
Las interacciones digitales
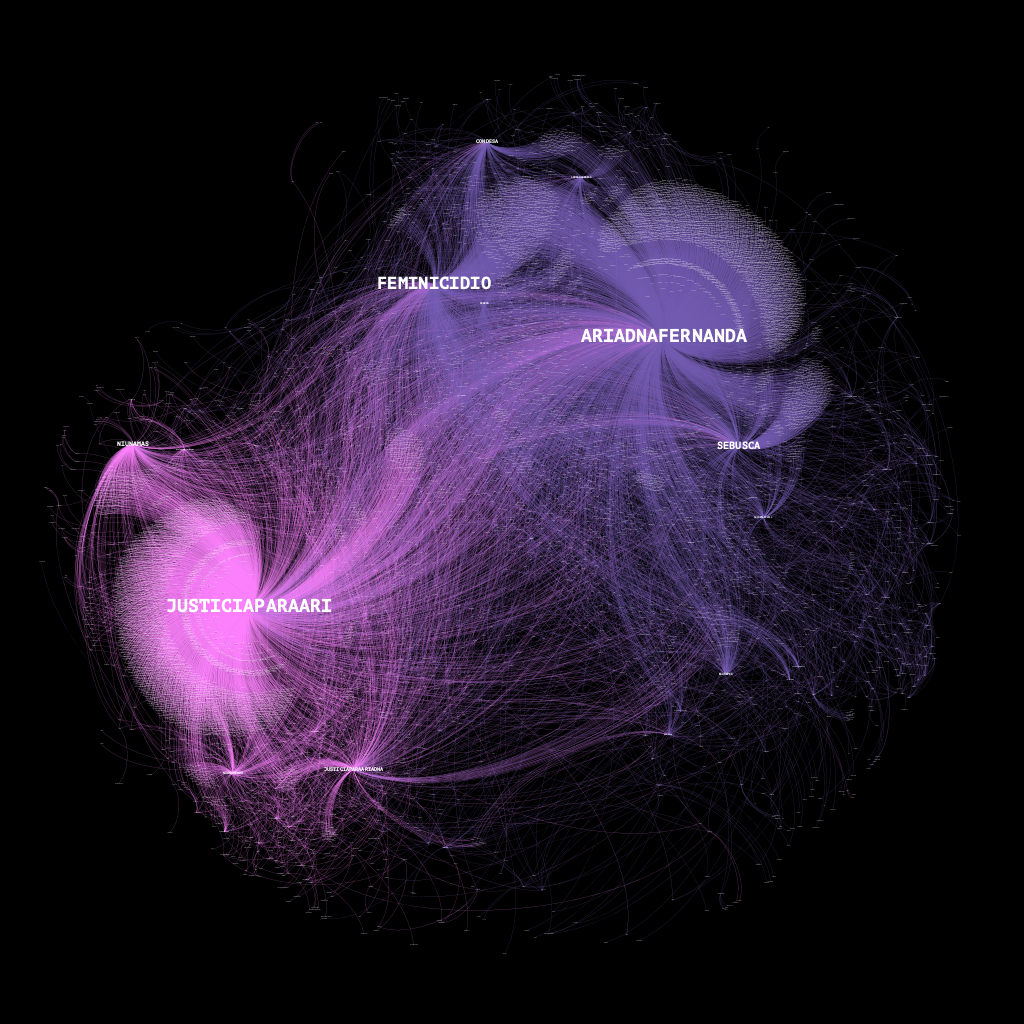
Para explorar una capa adicional de esta muestra de mensajes, graficamos las interacciones entre usuarios y los hashtags más usados en la conversación. El Grafo 1 consiste de 21,519 nodos y 45,695 aristas que construyen entre sí 59 comunidades. Es posible encontrar las etiquetas o hashtags más usados en la conversación entre el 3 y 10 de noviembre pasados.
Los hashtags con mayor preponderancia fueron #AriadnaFernanda (in-degree 9955) seguido de #JusticiaParaAri (in-degree:6993). El segundo expresa más la dimensión del reclamo en tanto que el primero, con el nombre de la víctima, capta parte del mismo pero también fue usado por los outlets informativos para construir los públicos digitales en torno al feminicidio.
Grafo 1: Interacciones entre usuarios y hashtags (U2HT). N: 21519; E: 45,695. A partir de una muestra de 85,903 mensajes en Twitter con los términos: “caso Ariadna”, “Rautel N”, #JusticiaParaAri y #AriadnaFernanda.
En importancia aparecieron otras etiquetas como #UltimaHora (in-degree:3648) y #Feminicidio (2727), además de #Video (2107) que podrían haber condensado parte de la conversación de medios informativos, sobre todo tras la revelación del video que muestra a Ariadna Fernanda llegando a un restaurante donde se encuentra con sus presuntos victimarios, Rautel y Vanessa “N”.
También aparecen hashtags como #CDMX, #Morelos, #ImagenesFuertes y #Rautel. Como se ve, las etiquetas con mayore preponderancia siguen las discusiones informativas. No obstante eso, #JusticiaParaAri es la segunda de mayor importancia y alrededor de ella se condensa buena parte de la conversación.
Otra cosa a considerar es que, entre los usuarios con mayor presencia por grado de salida, hay cosas qué distinguir: la cuenta con mayor número de mensajes fue @notasausencia, un perfil que documenta casos de desapariciones de mujeres y que forma parte del núcleo de activismo feminista en redes sociodigitales. Las otras cuentas están repartidas entre usuarios que se expresan (ya sea en sus perfiles o prácticas) como a favor o en contra del actual gobierno federal, seguidos de periodistas (@anafvega, @corresponsalesMX, @AztecaNoticias, entre otras).
Aunque se esperaba ver a más cuentas de activismo entre las más activas, en realidad son las cuentas mediáticas y los usuarios que confrontan sus filiaciones políticas los más prolíficos en número de mensajes emitidos.
Es decir, la discusión sobre el feminicidio de Ariadna Fernanda se ha plasmado, en primer lugar, en una contienda mediática y, en segundo lugar, en reclamo colectivo de justicia. De hecho, al explorar con mayor detalle las comunidades, esta afirmación puede mantenerse.
En el Grafo 2 se muestran dos comunidades. La de mayor tamaño en la esquina superior derecha tiene, ante todo, discusiones en tono informativo sobre el caos. En tanto, la siguiente, en la parte inferior izquierda concentra las etiquetas de reclamo de justicia para Ariadna Fernanda.
Grafo 2. Comunidades de mayor tamaño en la conversación.
La primera comunidad cuenta con 6,677 nodos y 11,082 aristas captando el 21% de la conversación. La segunda comunidad en torno a #JusticiaParaAri es ligeramente menor en tamaño y densidad (5,575 nodos y 6,789 aristas) pero es ahí donde se discute el reclamo de justicia. Las etiquetas con mayor grado de entrada ahí son #JusticiaParaAri (in-degree 6,693) seguida de #NiUnaMas (600), #JusticiaParaAriadna (477), #NiUnaMenos (296) y emergen, ahí mismo, otros llamados: #JusticiaParaLidiaGabriela, #JusticiaParaFer, #MexicoFeminicida, entre otros.
El Grafo 3 es uno de interacciones entre usuarios (usuario-a-usuario) y consta de 36,219 nodos y 85,300 interacciones entre ellos, alrededor de 187 comunidades. Es en estas interacciones donde se hace visible que las comunidades de discusión pendulan entre lo informativo, la politización del caso y el activismo en reclamo de justicia.
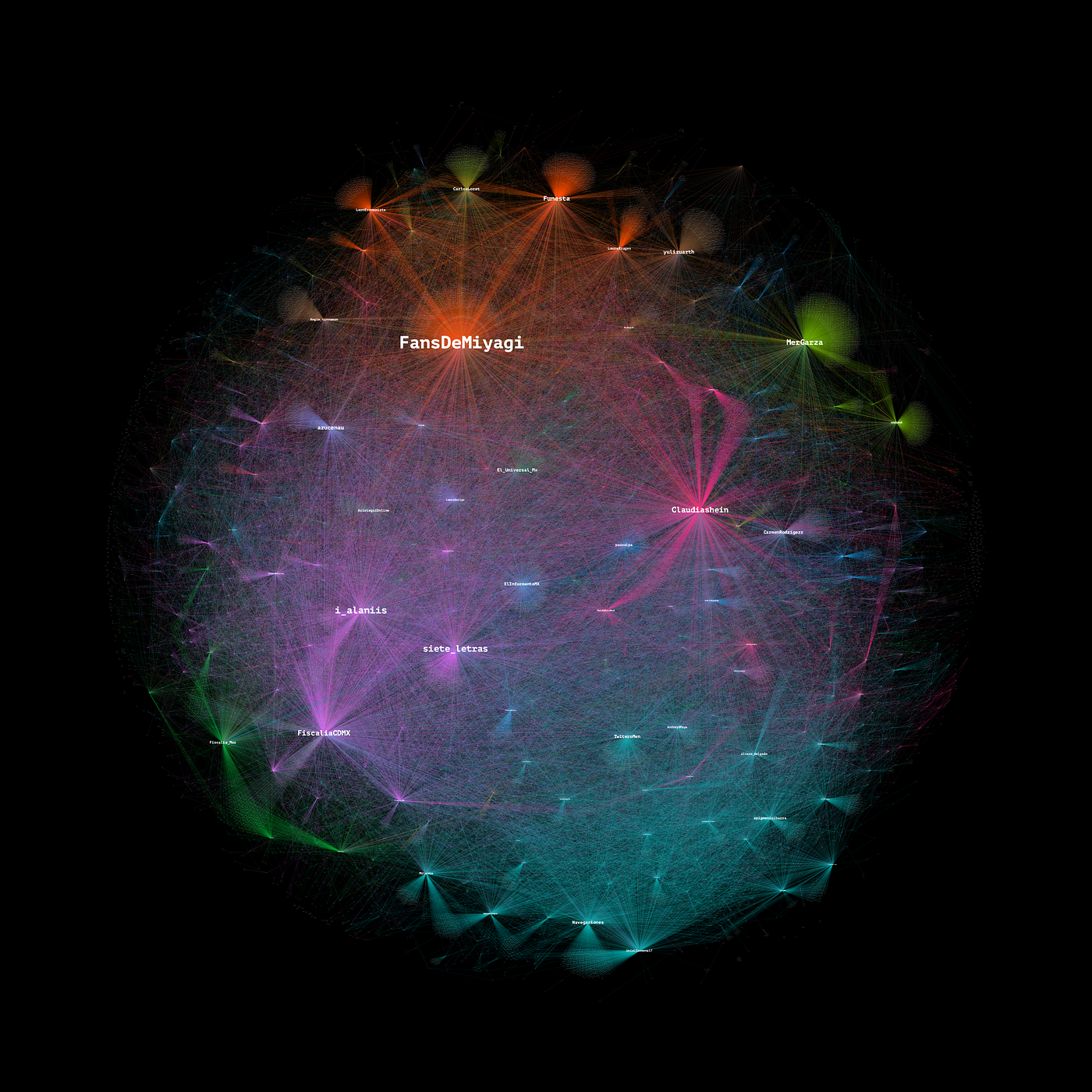
Grafo 3. Interacciones entre usuarios (U2U). N: 36,219, E: 85300. A partir de una muestra de 85,903 mensajes en Twitter con los términos: “caso Ariadna”, “Rautel N”, #JusticiaParaAri y #AriadnaFernanda.
A destacar, antes que nada, los usuarios con mayor grado de entrada (ya sea porque recibieron un mayor número de retuits o menciones). Se trata de la cuenta @FansDeMiyagi (in-degree 4805) que aborda distintos temas y tiene cierto grado de micro-influencia por su número de seguidores (más de 19K) y que desde el primer momento empezó a emitir mensajes para alertar de la desaparición de Ariadna Fernanda. Sus publicaciones adquirieron después un mayor tono de reclamo.
La segunda cuenta en importancia es la de la jefa de gobierno, @Claudiashein (in-degree 3919) cuya presencia en la discusión aumentó tras usar los espacios de sus conferencias de prensa para confrontar al fiscal de Morelos, Uriel Carmona. Otras cuentas relevantes fueron la @FiscaliaCDMX in-degree 3060), la activista @MerGarza (2517), el reportero de NMas, Antonio Nieto @siete_letras (2275), y la de la periodista Itzel Cruz @i_alaniis (2165).
También fueron relevantes por grado de entrada la cuenta activista @Funesta, la académica @yulizuarth, la periodista @azucenau, y las cuentas del fiscal de Morelos @UrielCarmona17 y su @Fiscalia_Mor.
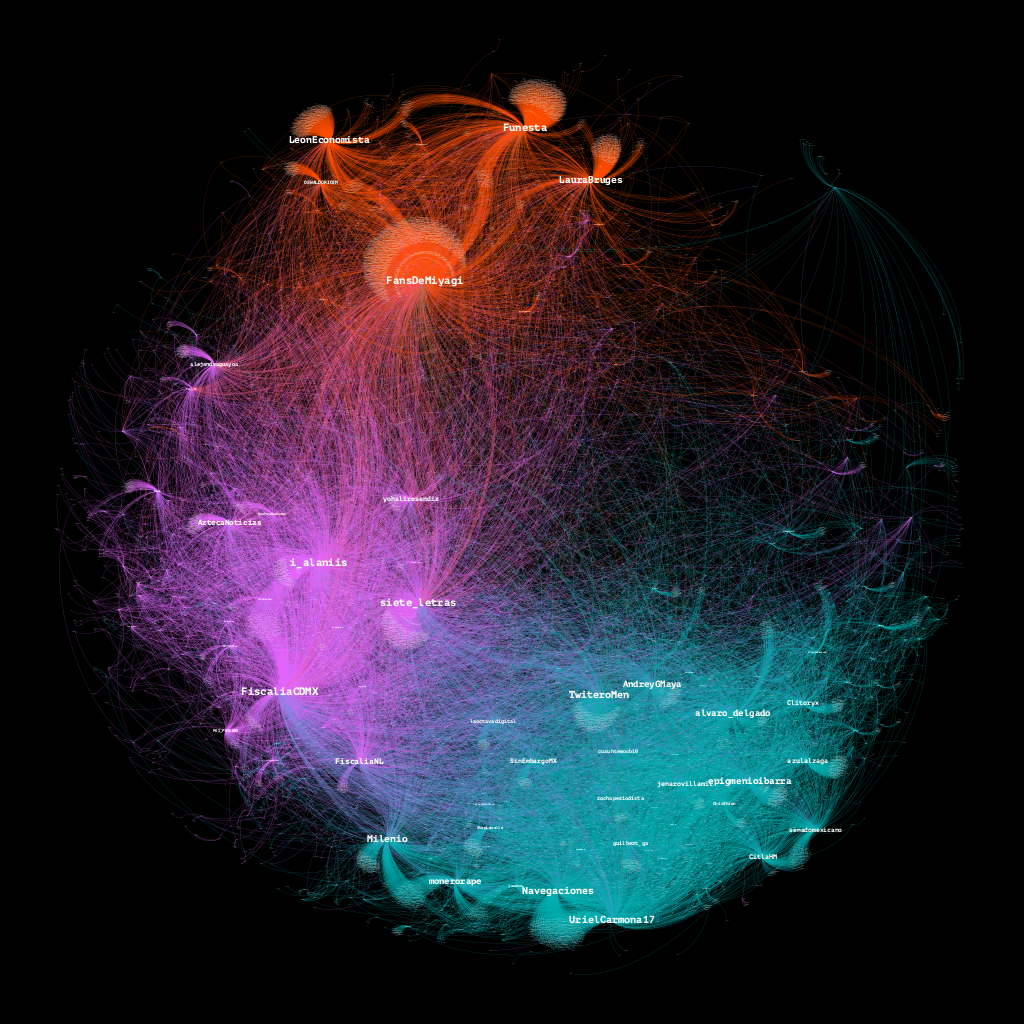
Al explorar las comunidades de mayor tamaño encontramos en el Grafo 4 que hay tres núcleos de discusión.
Grafo 4. Comunidades de mayor tamaño y densidad.
En la primera se concentra el 17% de la conversación, es la que se halla en la esquina inferior derecha y en la que, además de cuentas de medios de comunicación, se encuentran usuarios pertenencientes a la denominada 4T. Parece ser un núcleo donde el feminicidio de Ariadna Fernanda ha sido más politizado que discutido en tono de reclamo de justicia.
Esa primera comunidad está directamente enlazada a la tercera de mayor tamaño, que con el 11.61 de los nodos se encuentra en la zona central izquierda. Ahí se conforma la discusión mediática del feminicidio de Ariadna Fernanda. Está en comunicación con la zona de discusión política y presenta, además de a periodistas y medios, a la @FiscaliaCDMX.
Es la segunda comunidad en importancia, con su 15% de la conversación en la zona superior izquierda donde se pueden ver cuentas como @FansDeMiyagi o @Funesta que discuten desde la dimensión del reclamo.
En este tablero se pueden explorar los tuits por usuario y número de retuits, ubicando a algunos de los usuarios aquí citados. De hecho, una primera exploración permite ver que los tuits de #JusticiaParaAri son los más importantes pero, conforme se avanza en la búsqueda, las discusiones informativas (y aquellas que reproducen la confrontación entre autoridades de CDMX y Morelos) empiezan a adquirir relevancia en la producción de mensajes.
Mediatización y politización invisibilizan la injusticia
Si bien, la cobertura de los medios y la forma en que los personajes políticos discuten acontecimientos como es el feminicidio de Ariadna Fernanda, muchas veces la forma en que nos representan los hechos estos espacios mediáticos hacen que se pierda de vista o incluso, se deje en segundo plano la gravedad del fenómeno en cuestión y la necesidad del reclamo de justicia.
La indignación, la rabia y la tristeza que embarga a los familiares y amistades de las víctimas, así como a un país continuamente agraviado por la injusticia y la violencia, quedan en segundo plano cuando el encuadre de los medios mantiene como relevante la disputa política y politizada entre sectores de partido o interés cuyas omisiones revictimizantes, sin duda, deben ser juzgadas, condenadas y castigadas.
La descarga de datos ha permitido explorar la discusión de los últimos días. Para captar más elementos de la complejidad de las interacciones sociodigitales, en lugar de un solo término de búsqueda o una sola etiqueta/hashtag, se realizó una búsqueda combinada de términos, palabras y etiquetas. Esto permitió captar distintas comunidades de discusión que a su vez, nos permiten proponer una interpretación de cómo se construye la discusión ciudadana en espacios sociodigitales sobre el fenómeno de la violencia feminicida en nuestro país.
Esta publicación apareció originalmente en Medium el 17 de marzo de 2022
El próximo 10 de abril se llevará a cabo, por primera vez en México, un ejercicio de consulta para revocar el mandato al presidente de la república. El nuevo instrumento de participación ciudadana fue una de las promesas de campaña del actual presidente, Andrés Manuel López Obrador (AMLO), y fue aprobada por la Cámara de Diputados y el Senado de la República en septiembre de 2021.
Aunque prevista como un instrumento para retirar de su cargo a un presidente por “pérdida de la confianza” de la ciudadanía, han sido simpatizantes del mandatario emanado del partido Movimiento Regeneración Nacional (MORENA) quienes recabaron las firmas necesarias para solicitar la consulta. Tras el escrutinio de la solicitud ciudadana,el Instituto Nacional Electoral (INE) convocó en febrero pasado para que el próximo 10 de abril la ciudadanía acuda a las urnas y decida si el presidente continúa en el cargo.
La organización del ejercicio de revocación de mandato ha sido objeto de disputa política en distintos momentos pero, en lo que respecta a los preparativos y su organización, las diferencias se han intensificado. El presupuesto solicitado por el INE para sus funciones durante 2022 incluía una partida para la revocación de mandato, pero el requerimiento no fue aceptado por el Poder Legislativo (encargado de la aprobación de presupuesto) y finalmente, la Suprema Corte ordenó al instituto acatar los recortes y organizar el ejercicio. Por su parte, el presidente AMLO ha lanzado severas acusaciones al instituto (respecto al presupuesto, la organización y cumplimiento del ejercicio); la última tuvo lugar en días pasados cuando el mandatario acusó al instituto de no promover la consulta como parte de una estrategia golpista contra su gobierno.
Al igual que en otros momentos de la efervescencia política del país, la consulta de revocación de mandato en México también ha formado parte de la discusión digital. Sin embargo, parece ser que el tema no ha logrado la tracción que otros momentos de la vida política han tenido (las elecciones intermedias de 2021, por ejemplo).
A su vez, los espacios sociodigitales siguen siendo un territorio de disputa discursiva pero, también, de construcción colectiva del significado de los hechos políticos contemporáneos. En el caso de Twitter, no queda duda de su rol como espacio para la difusión de información y construcción de sentido sobre los eventos del momento (Sued y Cebral, 2020), mientras que muchos estudios han destacado el papel que cumplen estas plataformas ya sea para conectar a la ciudadanía con sus representantes políticos sobre todo en periodos electorales (Biswas et al., 2014), para impulsar a ciertos personajes en sus aspiraciones (Sobaci et al., 2016) o como fuente de información y movilización en procesos electorales (Barredo, Rivera y Amézquitan, 2015).
Algunos abordajes sobre la vida política nacional señalan por una parte el componente de polarización discursiva que ocurre en Twitter. El proceso electoral de 2021 dio cuenta de ello en torno al rol del INE en la organización del ejercicio (Véase, por ejemplo, el apartado El INE en Twitter, una hipótesis fallida, en el informe realizado por Signa_Lab al respecto). Sin embargo, también se ha dado cuenta de la apropiación del discurso político por parte de la ciudadanía y la forma en que se abordan fenómenos que ocurren en el contexto de procesos electorales, como la reciente pandemia de COVID y la violencia.
Aunque consideremos importante analizar el potencial de movilización electoral de las plataformas sociodigitales, en este caso y ante la cercanía del ejercicio de revocación de mandato (y su carácter sui generis en el contexto político mexicano) parece factible aproximarnos al fenómeno a partir del rol de difusión de información y encuadramiento simbólico que las redes sociales en general y, en este caso, Twitter, cumplen. Por ello, se ha decidido explorar algunos datos provenientes de este servicio para indagar sobre qué se está diciendo sobre la revocación de mandato.
¿Qué se discute en Twitter sobre el ejercicio de revocación de mandato? A partir de esta interrogante, trataremos de captar distintas dimensiones: por una parte, las interacciones entre usuarios a partir de este tema; dichas interacciones tienden a agruparse en comunidades de discusión, por ello, también trataremos de captar qué se comunica en dichos espacios discursivos; a partir de estos dos elementos, quizá sea posible acercarnos a los distintos encuadres propuestos por los actores que se han involucrado en el debate público digital.
#RevocaciónDeMandato: poca densidad de la discusión para un ejercicio nacional de participación ciudadana
Para este ejercicio, se extrajeron publicaciones que utilizaran el hashtag #revocaciondemandato (sic) en Twitter. La descarga se realizó mediante el software R (R Core Team, 2021) y la librería ‘rtweet’ (Kearney, 2020). El resultado fue un conjunto de datos conformado por 9,593 tuits que abarcan un periodo que va del 9 al 17 de marzo (Nota 1). Las publicaciones obtenidas no contemplan retuits, por lo que se tratan de tuits únicos u originales.
Cabe señalar que se exploraron otras etiquetas (#AmloSeQueda, #QueNoSiga, #QueSigaLaDemocracia, etc.) pero la cantidad de datos ofrecidos para este periodo era mucho menor. Esto por un lado, nos deja con un hashtag (HT) temático, que no plantea una postura de inicio (ya sea por la formulación propuesta o la combinación de palabras) como sí podrían estarlo planteando otras opciones y que nos habrían llevado a otro tipo de preguntas y resultados. Por ejemplo, algunos como #AmloSeQueda o #QueSigaAmlo están claramente apoyando el ejercicio y la “ratificación” de mandato al presidente mientras que otros son claramente opuestos (#QueSeVaya, #QueNoSiga) y que, de haberse extraído -ya sea por separado o en conjunto- habrían dado como resultado una clara polarización producto del propio diseño de la búsqueda. En su lugar, el HT #revocaciondemandato alude en principio al ejercicio, aunque otras etiquetas pueden co-ocurrir con esta, como se explorará más adelante.
Identificando comunidades por principio de modularidad
Como primer paso, del conjunto de datos se extrajeron las variables screen_name y hashtags para crear una matriz de adyacencia a partir de la cual se pudiera conformar un grafo de usuarios-a-hashtags. Posteriormente, se extrajeron, además del screen_name, los valores mentions_screen_name, quoted_screen_name, in_reply_to_screen_name. A partir de estas variables se construyó una segunda matriz de adyacencia para obtener un grafo de usuario-a-usuario para las interacciones mención, retuit citado y respuesta.
Los datos fueron cargados en el software Gephi (Bastian et al., 2009) y se sometieron al mismo tratamiento: cálculos a nivel de nodo, cálculo de modularidad para estimar comunidades, tamaño de nodos y etiquetas por grado (entrada o salida, según se indique), colores de aristas por comunidad, distribución mediante Force Atlas 2.
El primer grafo es el de usuario-a-usuario (U2U) que cuenta con 4,738 nodos y 7,797 aristas o interacciones. Cada nodo cuenta con un grado medio de 1.64, lo que indica un bajo número de conexiones entre nodos aunque cabe esperar que algunos concentren gran cantidad de las mismas. El cálculo de modularidad (0.6) produjo 839 comunidades.
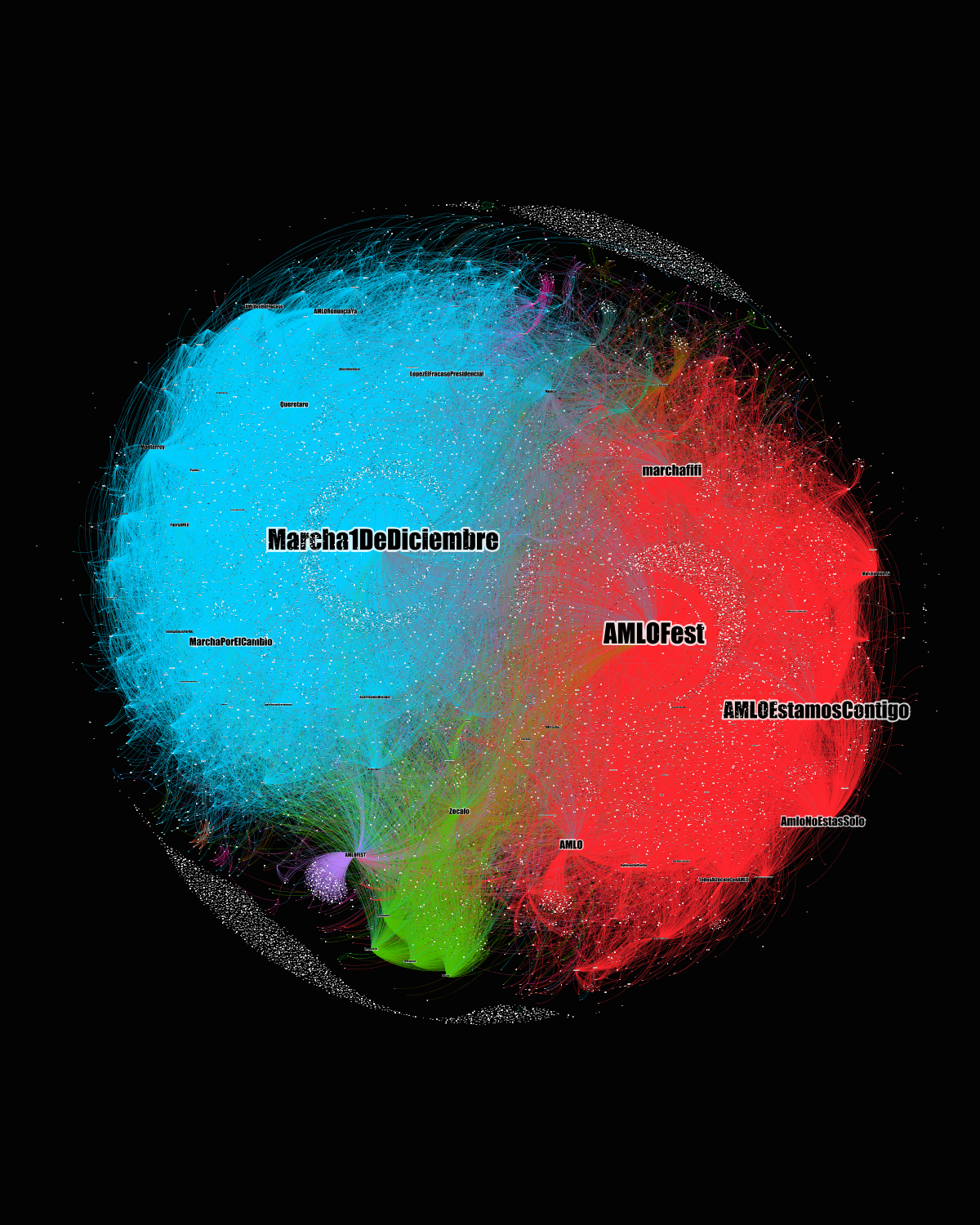
Algo a tener en cuenta en el Grafo 1 es que tres comunidades destacan por su tamaño (comunidad 12, con 15.41% del grafo; la 3 con el 10.36% y la 314 con 9.9%).
Grafo 1. Interacciones entre usuarios (U2U). El tamaño de las etiquetas es proporcional al grado de entrada (N: 4,738, E: 7,797)
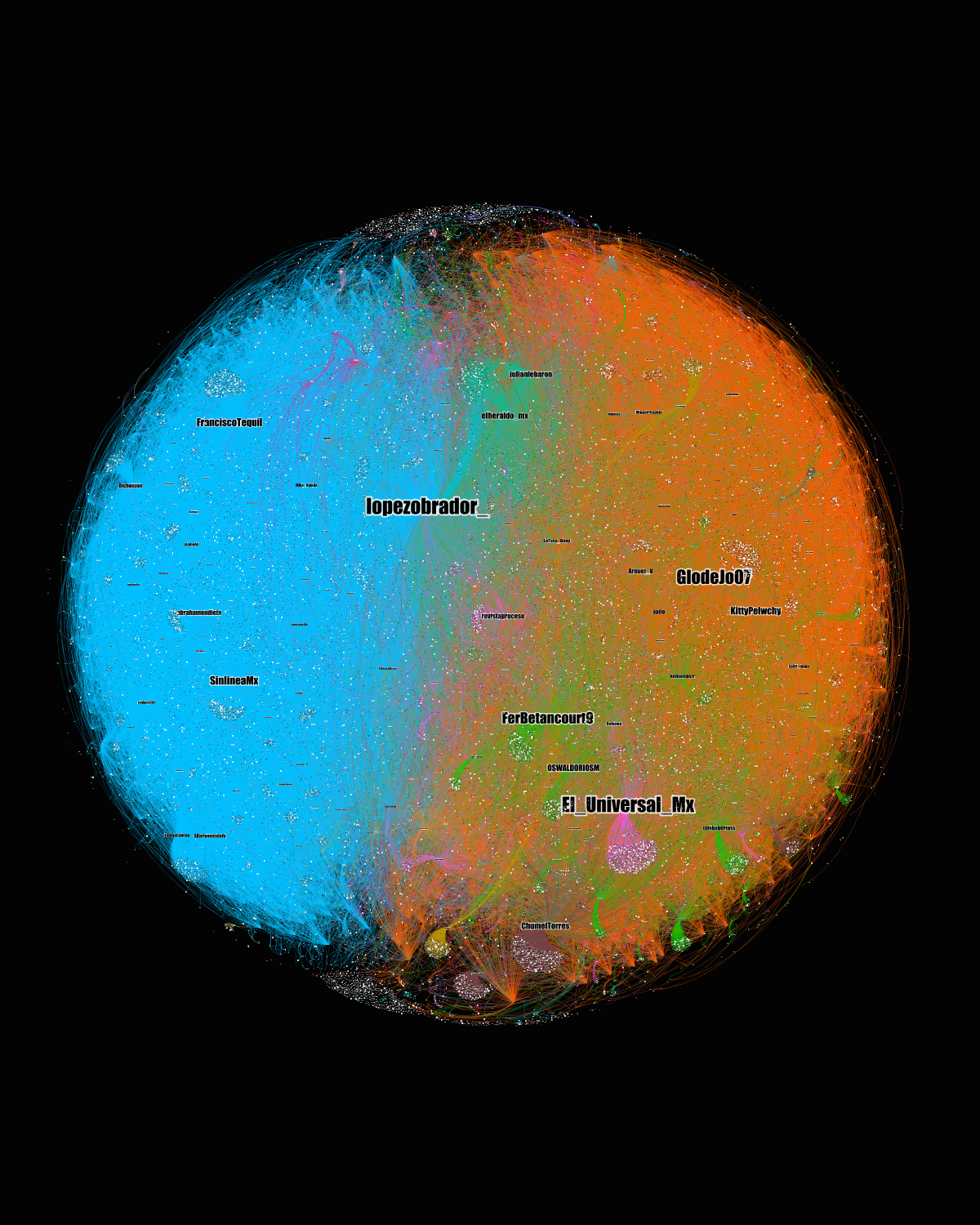
Las comunidades en las que se concentra mayor grado de entrada indican una distribución de cierto tipo de usuarios. En la comunidad azul claro muestra a la cuenta oficial del INE (@INEMexico) al centro y muy cerca a las de los consejeros @CiroMurayamaINE y @LorenzoCordovaV, como el target de múltiples menciones provenientes de variados usuarios. Una segunda comunidad violeta coloca con mayor centralidad a la cuenta del @PartidoMORENAMx seguida en cercanía por la de la jefa de gobierno de la Ciudad de México (del mismo partido) @ClaudiaShein, así como las cuentas oficiales del Poder Legislativo y la del presidente de MORENA, @mario_delgado. Una tercera comunidad en color verde muestra cuentas de comunicadores como @lopezdoriga, @CarlosLoret, @ChumelTorres, @PedroFerriz así como otros usuarios.
En términos generales, al destacar el grado de entrada, lo que estamos viendo son interacciones dirigidas a tres tipos de usuarios: por un lado, a la autoridad electoral o sus integrantes, posteriormente a miembros de MORENA y en tercer lugar, a integrantes de los medios de comunicación. No omitimos que el usuario del presidente AMLO (@lopezobrador_) se encuentra al centro de otra comunidad naranja que está prácticamente al centro del grafo, lo que implica cierta cercanía con las comunidades antes señaladas.
La forma en que se tejen y dirigen las interacciones en Twitter podría estar señalando encuadramientos discursivos específicos para ciertos tipos de usuarios (autoridades electorales, personajes del oficialismo -la autodenominada 4T- y de los medios de comunicación) así como al presidente de la república, objeto del ejercicio de #revocaciondemandato.
Los hashtags, como hicimos en este caso, no son solo útiles para identificar mensajes temáticos o como criterio de extracción. Varios estudios han señalado que el uso de estas etiquetas tiene cierto carácter estratégico por parte de los usuarios. Sirven para crear públicos ad hocpara cierto tipo de tópicos (Xu y Zhou, 2020) o para proponer encuadres simbólicos (interpretación o posición de los usuarios respecto a ciertos temas, como señalan Blevins et al. 2019). Por ello, se ha construido un Grafo 2 que muestra interacciones de usuarios-a-hashtags (U2HT).
El Grafo 2 consta de 4,590 nodos y 8,881 aristas (grado medio: 1.9, modularidad 0.53 para 90 comunidades). Las relaciones entre usuarios y hashtags es más densa que en el grafo anterior y contamos con comunidades más robustas (comunidad 9 con 43.36% del grafo, la 6 con 19.8 y la 1 con 16.06%). Esta mayor densidad de comunidades nos permite afirmar cierto grado de sistematicidad en el uso de etiquetas específicas.
Grafo 2. Interacciones entre usuarios y hashtags (U2HT). El tamaño de las etiquetas es proporcional al grado de entrada. (N: 4,590, E: 8,881)
Lo primero a reconocer es que la formulación de la frase “revocación de mandato” aparece con distinciones (uso de mayúsculas, acentuación) lo que dispersa algunas comunidades. Pero esto podría ser indicativo de un uso particular de la etiqueta si analizamos el grafo a detalle.
Cuando el HT no lleva acento (#RevocacionDeMandato) en la comunidad naranja (zona superior izquierda) este se asocia con etiquetas de rechazo al ejercicio o algunas utilizadas por grupos opositores al actual gobierno (#UrnasVacias, #NoALaRevocacionDeMandato, #amlofracasopresidencial, #SiVotaSeVa, #TerminasYTeVas entre otros).
En tanto, cuando el HT sí utiliza acentos (#RevocaciónDeMandato) encontramos otra comunidad (verde, inferior derecha) en la que hay una serie de etiquetas que son usualmente movilizadas por las cuentas oficiales del INE nacional y en los estados (#INEMexico, #MiINENosUne, #10DeAbril, #ListaNominalDeElectores).
Finalmente, las dos comunidades centrales (azul y violeta) muestra mayor asociación con etiquetas de apoyo al ejercicio desde la simpatía al movimiento 4T (#AMLO, #QueSigaAMLO, #MORENA).
Estas dos exploraciones dan cuenta entonces de que por una parte hay interacciones, ya sea orientadas hacia cierto tipo de actores (autoridad electoral, gobierno y medios de comunicación) aunque también puede estar habiendo cierto grado de amplificación en los mensajes de dichos sectores (cosa que debe analizarse a partir de los metadatos pero que, dado el Grafo 1, cabría esperar). Por otra parte, parece estarse dando cierto grado de uso estratégico del HT #RevocaciónDeMandato igualmente en tres sentidos: como elemento informativo desde la estrategia de comunicación de la autoridad electoral, como elemento de crítica de quienes se oponen al ejercicio y como reforzamiento ideológico desde quienes lo apoyan.
Para abundar en estos elementos, se llevó a cabo un post-procesamiento de los datos: tras obtener el cálculo de modularidad para ambos grafos, se asignó a cada usuario el valor de la comunidad a la que correspondía. El objetivo es explorar el contenido de los mensajes a partir de la comunidad de interacciones de la que el usuario formaba parte.
Comunidades discursivas: discusión, debate, respaldo y crítica en torno a la #RevocaciónDeMandato
El tratamiento de los datos y la visualización que se ofrece de los mismos se produjo mediante el software Tableau (Tableau Software, 2021) en su versión pública. Todas las visualizaciones están disponibles en un tablero en línea que puede consultarse en este enlace.
La Tabla 1 muestra la distribución de las publicaciones con #revocaciondemandato (sic) en el periodo observado. El eje vertical muesra el alcance de los mensajes. Las tres publicaciones con mayor número de retuits pertenecen, en orden: al personaje opositor Javier Lozano quien compartió una imagen de rechazo al ejercicio de revocación de mandato, un mensaje de texto acompañado por un video del actor Damián Alcazar expresando su apoyo al ejercicio, y un mensaje de la jefa de Gobierno, Claudia Sheinbaum en el que critica la orden del INE de retirar propaganda gubernamental durante el periodo del ejercicio electoral.
Tabla 1. Distribución de publicaciones con el hashtag #revocaciondemandato para el periodo del 9 al 17 de marzo.
Como se puede observar, son pocos los mensajes que logran un alcance mayor a los 500 retuits, y pertenecen en su mayoría a personajes políticos, medios de comunicación, cuentas oficiales y escasas micro-celebridades (usuarios con alto número de seguidores). Esto se corresponde con el hecho abordado por Sued y Cebral (2020) de que ciertas “voces autorizadas” que cumplen determinadas funciones sociales (gobierno, medios, periodistas, autoridades, etc.) logran mayor adhesión a sus mensajes, lo que se traduce en un alcance más alto por retuits o involucramiento anímico mediante el botón de Me Gusta (Favorito).
Así, una gran capa de usuarios con poco alcance integra una alfombra de publicaciones con limitado alcance pero en la que, sin duda, se está dando parte de la discusión que se apoya en el encuadre simbólico que las denominadas “voces autorizadas” proponen, ya sea para apoyarlas, discutir con ellas o rebatirlas.
Se ha decidido llamar “comunidades discursivas” a los espacios de construcción de sentido que surgen en torno a ciertas propuestas de enmarcamiento provenientes de lo que Sued y Cebral (2020) llamaron “voces autorizadas”. Las comunidades identificadas en los grafos cuentan con nodos que acumulan cierto grado de centralidad (que en los metadatos estaría representado por número de retuits o favoritos) y en torno a los cuales hay discusión (en concordancia o discordancia con el encuadre simbólico propuesto por dichas voces autorizadas).
Para tratar de identificar estas comunidades discursivas utilizamos la variable Comunidad proveniente del cálculo de modularidad y la asignamos a las publicaciones de Twitter recabadas previamente. En la Tabla 2 se encuentran los mensajes distribuidos por color (para cada comunidad) y tamaño (por número de retuits). Lo que esperamos ver a partir de esta estrategia es qué mensajes tuvieron más alcance en cada comunidad y qué encuadre proponen, así como las diferencias entre comunidades discursivas. (Recomendamos visitar el tablero en línea para explorar estos elementos a mayor detalle)
Tabla 2. Los colores representan las distintas comunidades calculadas en el grafo de interacciones entre usuarios. El tamaño se corresponde con el número de retuits conseguidos. Al navegar en las publicaciones pueden obtenerse detalles de los usuarios y al seleccionar alguna, ir a la publicación original.
Por economía de exposición, se darán detalles de tres de las comunidades más importantes.
La comunidad rosa (o magenta, 314) es la que, por alcance, acumula el mayor número de retuits. En ella se encuentran publicaciones claramente en oposición al ejercicio de revocación de mandato. Dos usuarios forman parte de grupos de oposición partidista (Javier Lozano, Xóchitl Gálvez) quienes critican duramente la próxima consulta. También se hallan mensajes de la periodista Azucena Uresti, en tono más bien informativo. Destaca que en esta comunidad discursiva aparece la publicación de la jefa de Gobierno, Claudia Sheinbaum. Es posible que esto se deba a las interacciones dirigidas a ella y que pudieron concordar con el tono de crítica que prevalece en esta comunidad.
La segunda comunidad de interés es la de color gris (zona inferior izquierda, 12). En alcance, es ligeramente menor a la primera y los mensajes más relevantes provienen de “voces autorizadas”, en este caso, autoridades electorales. La mayoría de los mensajes corresponden a cuentas oficiales del instituto en los estados. Sin embargo, también emergen publicaciones de otros usuarios que ya sea replican contenidos informativos o presentan cuestionamientos al ejercicio de revocación de mandato.
En importancia, la tercera comunidad es la color naranja (centro superior, 3). El usuario más relevante de esta comunidad es Gurú Político, un medio de comunicación digital, que ofrece un encuadre de apoyo al ejercicio de revocación. Le sigue el presidente del Sistema Público de Radiodifusión, el periodista Jenaro Villamil en un tono similar. Aunque el encuadre propuesto por estas cuentas que podrían funcionar en esta comunidad como “voces autorizadas” se muestra en favor de la revocación, gran parte de los mensajes con mayor alcance en este grupo cuestionan el ejercicio críticamente.
Hay que señalar que a excepción de la comunidad 12 (cuentas oficiales de autoridades electorales) que propone en su mayoría una discusión de corte informativo, en el resto de comunidades discursivas hay más bien posiciones a favor o en conra del ejercicio. Las comunidades más grandes o de mayor alcance discuten críticamente la consulta de revocación de mandato. Otras comunidades que siguen en importancia manifiestan cierto grado de apoyo, algunas más cuentan con voces autorizadas de medios de comunicación que presentan también discusiones informativas.
Otra forma de ver esta distribución es la siguiente gráfica que muestra el alcance en retuits por comunidad y el porcentaje que representan del total amplificación para todo el conjunto de datos.
Gráfica 1. Distribución del alcance, medido por número de retuits acumulados, para cada comunidad discursiva.
Lo que la idea de comunidad discursiva nos permite es aproximarnos al encuadre que proponen las y los usuarios que logran un mayor alcance (ya sea porque se trate de figuras relevantes para ciertos grupos o porque han logrado un mayor número de seguidores como parte de su presencia en la plataforma). Esto no debe implicar necesariamente que cada comunidad discursiva imputada acepta la propuesta de significado que producen dichos “notables”, sino que es a partir de ella que se teje la discusión.
Contamos así con espacios de interacción en los que hay una posición claramente en contra del ejercicio, otras en las que hay más apoyo al mismo, y otras en las que hay un tratamiento informativo de la consulta. Estas últimas cumplen, en términos de función social de la plataforma, el rol de difusores de información, sin embargo, sus espacios no están exentos del debate que los usuarios en general tienden a producir.
Los hashtags en la comunidades discursivas sobre la #RevocaciónDeMandato
Como se señaló antes, los hashtags pueden ser utilizados de forma estratégica por los usuarios, tanto para crear audiencias en torno a ciertos tópicos como para ofrecer cierto enmarcamiento (de posición o interpretación de los hechos) en el contexto de la discusión digital.
Partiendo de la noción aproximativa de comunidad discursiva, hemos explorado los mensajes de usuarios en torno a la #revocaciondemandato, pero hemos llevado a cabo un post-proceso adicional para tratar de ubicar los hashtags en correspondencia a las comunidades identificadas en las interacciones y que nos permitieron construir la visualización de comunidades de discurso.
A partir del cálculo de modularidad para el Grafo 2 asignamos a la tabla de aristas la comunidad correspondiente a sus nodos de origen (Source). El resultado puede explorarse en la Tabla 3 que también está disponible en versión interactiva digital.
Se deben señalar dos cosas importantes y que inciden en el análisis: estas comunidades son en principio, distintas a las del apartado anterior, pues el cálculo de modularidad se realizó sobre el Grafo 2. El segundo elemento es que debido a que un mismo nodo Target (o nodo de destino de la interacción) puede haber recibido interacciones de distintos nodos de origen (Source) algunas etiquetas duplican su presencia en distintas comunidades. Para reducir la redundancia, hemos filtrado los resultados eliminando de la visualización el hashtag con el que se realizó la búsqueda (#revocaciondemandato y formulaciones similares con mayúsculas o acentos).
El principio y las implicaciones para el análisis son, sin embargo, similares en este nuevo tratamiento de los datos, a saber, dado que hay un uso orientado para los hashtags, las interacciones alrededor de los mismos deberían formar cierto tipo de configuraciones discursivas que pueden hacerse visibles mediante el cálculo de modularidad.
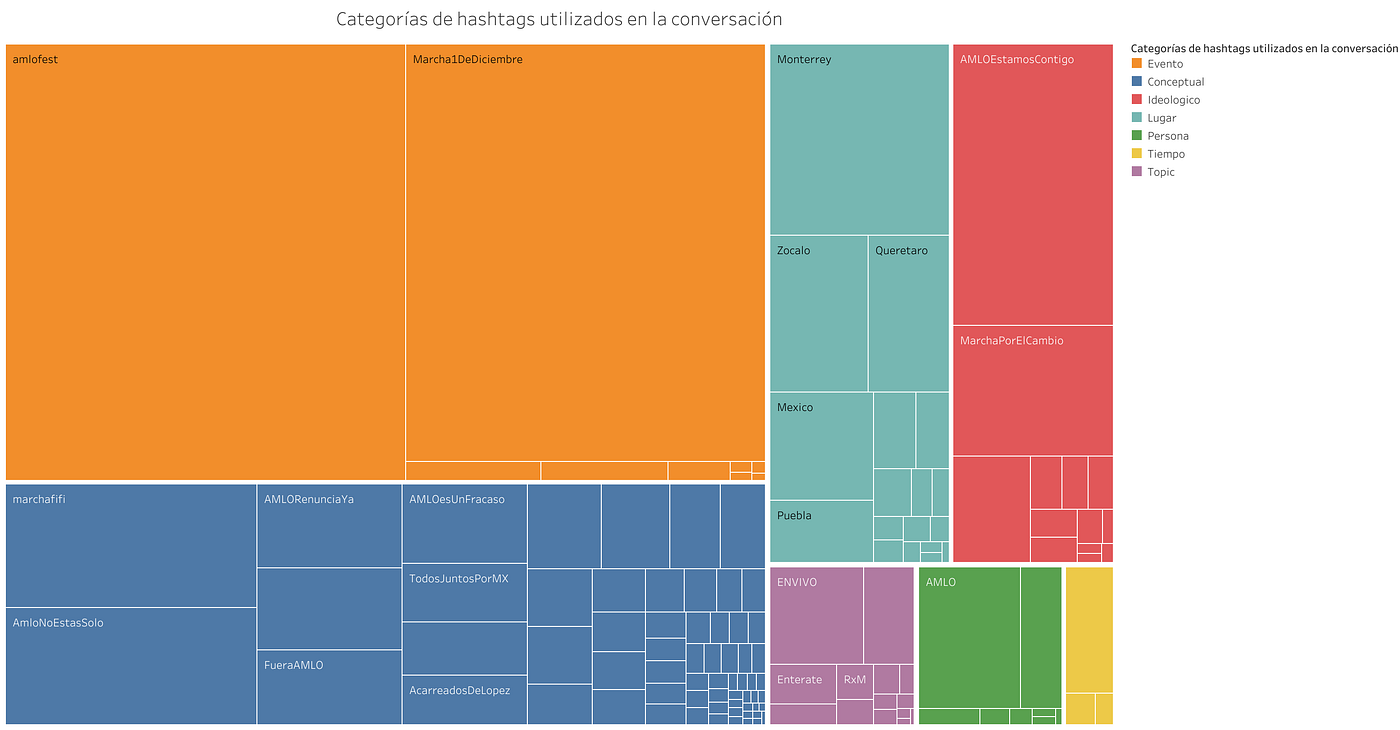
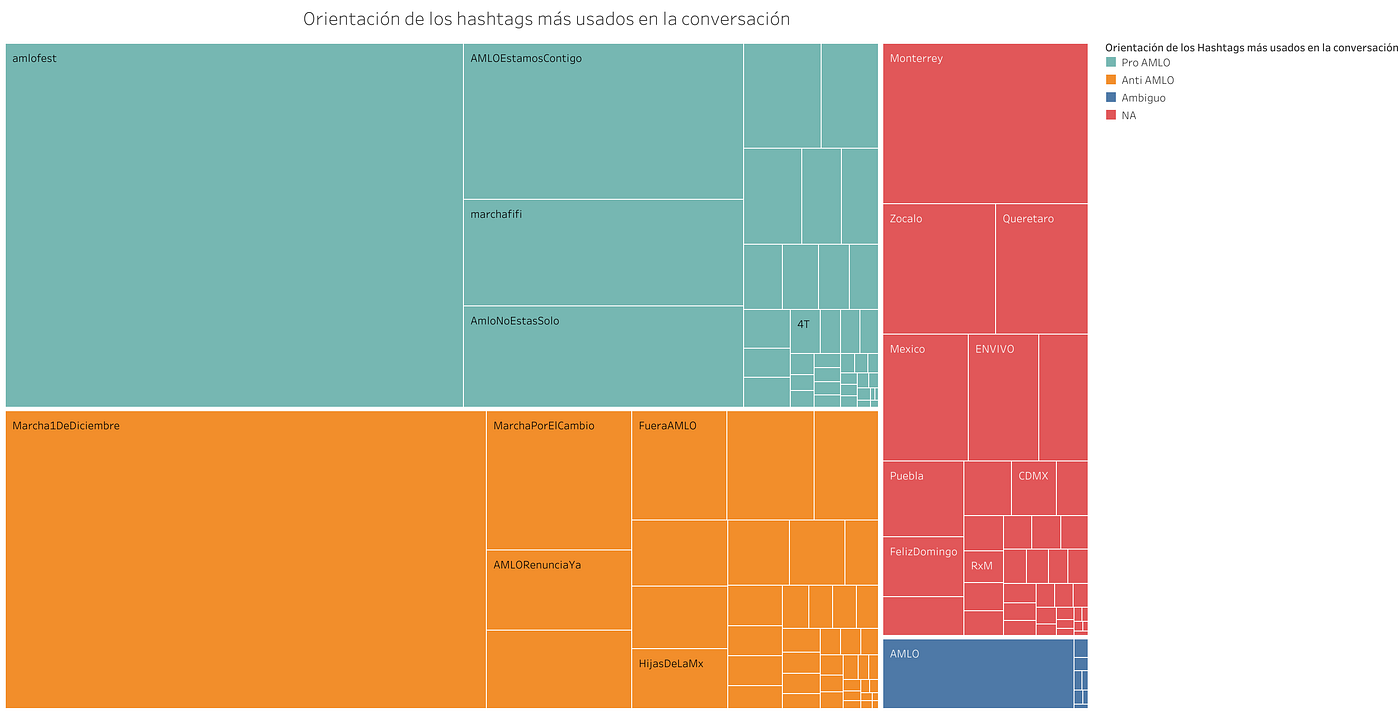
Tabla 3. Mapa de árbol para los hashtags. El tamaño se corresponde con el peso de la arista a la que pertenecían en el Grafo 2 y el color a la comunidad.
La premisa parece cumplirse. Para la comunidad celeste (1, superior izquierda) y que acumula el mayor grado de peso de las aristas, se forma una comunidad en torno a los hashtags informativos utilizados por las cuentas oficiales del INE nacional y de los estados. Esta comunidad se corresponde con la función social de difusión de información que ciertos usuarios (voces autorizadas) tienen en Twitter.
La segunda comunidad en importancia es la azul (inferior izquierda, 0) y en la que parece conformarse un encuadre de oposición en torno a hashtags como #SiVotasSeVa, #UrnasVacias, #VotasYSeVa, #CasaGris, #10DeAbrilLopezSeVa, #ElImbecilDePalacio, entre otros. Algo en lo que nos permite detallar esta visualización es que la oposición no es exclusivamente al ejercicio de revocación de mandato sino, más bien, hacia la figura en el poder o el proyecto de gobierno que se somete al mismo.
La tercera comunidad (superior derecha, 6) muestra una diversidad de posiciones discursivas: algunos elementos tienen corte informativo (#AIFA, #CDMX, #Nacional, #Entérate) y otras de corte político (#AMLO, #MORENA, #RevocacionDeMandatoVa, #SiPorMexico). En esta comunidad el uso de los HTs parece producir una conjunción entre propuestas informativas y discusiones del ejercicio de revocación de mandato, preferentemente de índole positiva.
Finalmente, una cuarta comunidad (roja, central, 10) manifiesta la propuesta de encuadre preferentemente positivo en torno a la revocación de mandato y el proyecto político de la 4T (#QueSigaAMLO, #QueSigaLaDemocracia, #AMLOSeQueda, #AMLONoEstasSolo, etc.) que, en términos del conjunto de datos, logra cierto grado de densidad y mayor uniformidad que otras comunidades discursivas.
Difusión informativa, discusión y participación hacia la #RevocaciónDeMandato
Partiendo de la pregunta ¿Qué se discute en Twitter sobre la revocación de mandato? se descargaron casi 10 mil tuits con el hashtag #revocaciondemandato (sic) de la plataforma de red social Twitter. Los datos resultantes se procesaron para mapear interacciones y detectar comunidades de discusión.
A partir de la identificación de comunidades, se asignó a los mensajes y los hashtags, espacios discursivos de pertenencia tratando de identificar encuadres simbólicos en torno al ejercicio de revocación de mandato, considerando factores como el alcance logrado por cierto tipos de usuarios y la correspondencia simbólica que se da en el uso de ciertas etiquetas en el marco de interacciones entre grupos de usuarios.
Como resultado de la descarga, se encuentra primero que nada que la discusión no es aún demasiado densa en torno al tema. El hashtag temático #revocacióndemandato aparece utilizado por múltiples usuarios, pero su densidad todavía es menor a otros temas del momento en el marco de la vida política nacional. Esto no es menor, pues el ejercicio se acerca y el 10 de abril la ciudadanía acudirá a las urnas para tomar una decisión a este respecto.
El mapeo de interacciones nos permitió identificar a qué tipo de usuarios se dirigen o se amplifican sus comentarios sobre la revocación de mandato: las autoridades electorales aparecen como centrales en su papel de difusión de información del ejercicio, personajes políticos del oficialismo (o la 4T) están presentes en la discusión tomando posición respecto al mismo, y la presencia de los medios de comunicación (con usuarios periodistas) aparece como prominente como parte de la cobertura al tema. Como en otros casos, la figura del presidente no deja de ser central, cabe señalar.
El uso de los hashtags parece seguir la lógica estratégica que otros estudios han reseñado, y termina asociado en tres sentidos: como elemento de información cuando proviene de autoridades electorales, como espacio para la crítica entre quienes rechazan el ejercicio electoral, y como punto de partida para reafirmar el apoyo al gobierno en turno entre quienes impulsan la revocación de mandato.
Estos elementos nos permitieron construir la noción de comunidades discursivas, retomando a la vez la propuesta de Sued y Cebral (2020) sobre “voces autorizadas” en tanto que usuarios que, al cumplir una función social en las plataformas, proponen también un encuadre simbólico para ciertos temas. Así, encontramos que voces autorizadas logran mayor alcance de sus mensajes y reúnen en torno a sí interacciones y discusiones que se corresponden o divergen de la propuesta discursiva planteada. En general, los temas se dividen, de nuevo, en tres: el manejo informativo de la revocación de mandato, la crítica (algunas veces severa) al mismo, y el respaldo al gobierno en turno y a la convocatoria a las urnas.
Al llevar la noción de comunidad discursiva al uso de hashtags, encontramos que las interacciones alrededor de los mismos reproducen esta lógica de construcción de encuadre, lo que refuerza nuestras aproximaciones previas.
Con ello, lo que parece surgir es el hecho de que si bien, el ejercicio de revocación de mandato no parece haber logrado densidad (en términos de producción de mensajes) en Twitter que otros temas han logrado, abre distintos espacios para la discusión (para informar, apoyar o criticar) sobre la próxima consulta. Esta falta de tracción que ha experimentado el tema en espacios sociodigitales podría deberse al hecho de que, debido a que siguiendo la ley en la materia, el INE ha instruido a las representantes de gobierno a no pronunciarse sobre el proceso.Esto podría cambiar en los próximos días luego de que la bancada de MORENA en el Poder Legislativo aprobara el pasado 17 de marzo un decreto que interpreta parte de la ley en la materia e interpreta el concepto de propaganda gubernamental (prohibido durante el proceso) estableciendo que “no constituyen propaganda gubernamental las expresiones de las personas servidoras públicas, las cuales se encuentran sujetas a los límites establecidos en las leyes aplicables”. Esto permitiría, en lo que aquí se ha discutido, que estas “voces autorizadas” en el escenario sociodigital participen activamente, proponiendo un marco de interpretación del proceso y generando ya sea adhesión a sus pronunciamientos o mayor discusión en torno a los mismos.
No se omite el hecho de que debido a la forma en que realizamos la consulta a la API de Twitter, la extracción deja de lado mensajes que aborden el tema sin utilizar el hashtag. Por ello, estas reflexiones se enmarcan en el uso estratégico de las etiquetas en plataformas de redes sociales (la utilización del HT como parte de una propuesta discursiva, ya sea para tomar posición o interpretar un evento). De ello se deriva que, para conocer a mayor profundidad el tema, se requieren estrategias que amplíen el espacio de observación hacia mensajes no etiquetados mediante esta práctica.
Notas
La versión 1 de la API de Twitter permite acceder a una ventana de datos de los últimos 7–10 días. Cada llamado a la API permite una descarga de unos 17,000 tuits. El espacio entre llamados a la API es de 15 minutos.
R E F E R E N C I A S
Barredo Ibáñez, D., Rivera, J., & Amézquitan, A. (2015, junio). La influencia de las redes sociales en la intención de voto. Una encuesta a partir de las elecciones municipales en Ecuador 2014. Quórum Académico, 12(1), 136–154.
Bastian, M., Heymann, S., & Jacomy, M. (2009).Gephi: An Open Source Software for Exploring and Manipulating Networks. International AAAI Conference on Weblogs and Social Media.
Biswas, A., Ingle, N., & Roy, M. (2014, junio). Influence of Social Media on Voting Behavior. Journal of Power, Politics & Governance, 2(2), 127–155.
Blevins, J. L., Lee, J. J., McCabe, E. E., & Edgerton, E. (2019). Tweeting for social justice in #Ferguson: Affective discourse in Twitter hashtags. New Media & Society, 21(7), 1636–1653. https://doi.org/10.1177/1461444819827030
R Core Team. (2021). R: A Language and Environment for Statistical Computing [R]. R Foundation for Statistical Computing. https://www.R-project.org/
Sobaci, M. Z., Eryiğit, K. Y., & Hatipoğlu, İ. (2016). The Net Effect of Social Media on Election Results: The Case of Twitter in 2014 Turkish Local Elections. En M. Z. Sobaci (Ed.), Social Media and Local Governments (Vol. 15, pp. 265–279). Springer International Publishing. https://doi.org/10.1007/978-3-319-17722-9_14
Sued Palmeiro, G. E., & Cebral Loureda, M. (2020). Voces autorizadas en Twitter durante la pandemia de COVID-19: Actores, léxico y sentimientos como marco interpretativo para usuarios ordinarios. Revista de Comunicación y Salud, 10(2), 549–568.
Xu, S., & Zhou, A. (2020). Hashtag homophily in twitter network: Examining a controversial cause-related marketing campaign. Computers in Human Behavior, 102, 87–96. https://doi.org/10.1016/j.chb.2019.08.006
Esta publicación reproduce un ejercicio realizado como parte del taller “R para Ciencias Sociales” impartido por Brenda Vázquez. A lo largo de este ejercicio se otorgan los enlaces para acceder a las bases de datos y se reproduce el código utilizado para el ejercicio.
El objetivo de este ejercicio es estimar qué tan asociado está el puntaje que obtienen películas de habla inglesa con el número de premios que reciben. La premisa es que aquellas cintas que reciben una mejor recepción de la crítica y la audiencia tienden a obtener un mayor reconocimiento institucional. Usaremos como variable independiente o explicativa el puntaje que obtienen películas de habla inglesa en el sitio Metacritic y como variable dependiente el número de premios recibidos.
Metacritic es un sitio en el que usuarios y sitios especializados valoran distintos tipos de productos culturales (desde películas y series hasta videojuegos y música).
Datos y técnicas
Los datos que utilizaremos para poner a prueba esta premisa fueron construidos por un estudiante originario de India, Syed Mubarak quien publicó en Kaggle una base de datos que contiene 9425 registros de películas y series disponibles en la plataforma Netflix. La base fue publicada en agosto de 2021 por lo que es una de las más recientes. Puede consultarse en el sitio de Kaggle.
El conjunto de datos ofrece 29 variables entre las que se encuentra el título, género, idiomas, duración, entre otros. Para la variable explicativa utilizaremos el puntaje obtenido en Metacritic (“Metacritic Score”) y para la dependiente el número de premios obtenidos (“Awards Received”) que forman parte de la base. Estas variables serán sometidas a un modelo de regresión linear para estimar el efecto que el puntaje tiene en el número de premios. Esperamos que aquellas películas más valoradas por los usuarios sean las que obtengan mayor reconocimiento.
Después de explorar los datos, notamos que existen títulos que no cuentan con datos. Para refinar el proceso, decidimos eliminar los datos perdidos así como aquellos que tuvieran menos de un premio. Como paso adicional, decidimos filtrar los registros para quedarnos únicamente con películas cuyo idioma fuera Inglés. Para llevar a cabo esto realizamos un subconjunto de datos a partir de la base original.
Del total de registros en el conjunto original, redujimos el número de observaciones a 988 películas en habla inglesa con al menos dos premios obtenidos.
Resultados
El siguiente paso fue explorar los descriptivos de cada variable.
summary(metapremios$`Metacritic Score`)
Min. 1st Qu. Median Mean 3rd Qu. Max.
6.0 52.0 66.0 62.9 75.0 99.0
summary(metapremios$`Awards Received`)
Min. 1st Qu. Median Mean 3rd Qu. Max.
2.0 3.0 5.0 12.7 13.0 242.0
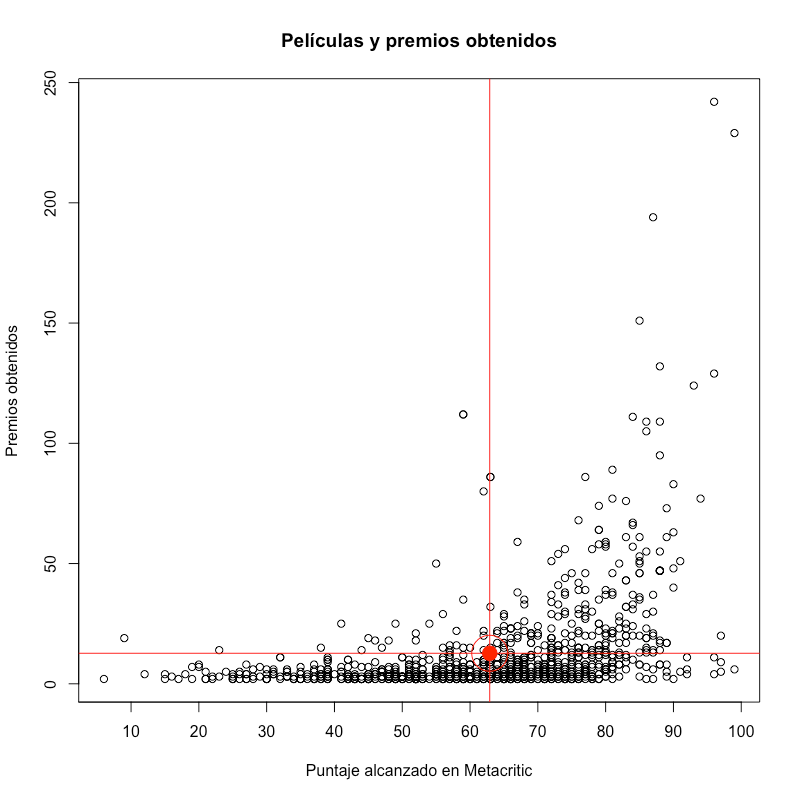
Así, encontramos que la media de puntaje en Metacritic para el conjunto de películas es de 62.9 y la media de premios es de 13 galardones. Mediante las siguientes líneas de código, graficamos los resultados y trazamos las líneas donde se cruzan las medias de cada una de las variables.
Gráfica de dispersión para películas por puntaje alcanzado en Metacritic y número de premios obtenidos.
Lo primero que cabe notar es que, aparentemente, películas con mayor puntaje en Metacritic obtienen un mayor número de premios, sin embargo, aún hay un alto número de películas que obtienen pocos premios pese a su alto puntaje. Cabe esperar que la correlación entre estas dos variables, si bien existe, no sea tan fuerte como esperábamos al principio. Para explorar esto, realizaremos una correlación simple entre ambas.
cor(metapremios$`Metacritic Score`, metapremios$`Awards Received`,
use = “pairwise.complete.obs”)
#[1] 0.3916265
Obtenemos un valor de 0.39 que nos indica una asociación no muy fuerte pero positiva entre el puntaje de la crítica y los premios recibidos. Hemos decidido realizar una exploración gráfica para ver cómo se distribuye la asociación. Para ello, utilizaremos ‘ggscatter’ que requiere instalar y cargar los paquetes ‘ggplot2’, ‘ggsci’ y ‘ggpubr’.
Gráfico de dispersión de la correlación entre Puntaje en Metacritic y Premios Obtenidos para películas en habla inglesa disponibles en Netflix.
Ahora podemos ver no solo el valor de la correlación (R=0.39) sino también su pendiente. Ahora que tenemos certeza de que las variables están asociadas, que su correlación es positiva y que ésta es estadísticamente significativa, procederemos a poner a prueba nuestra premisa calculando un modelo de regresión. Para obtener una versión más estilizada de los resultados del modelo, hemos cargado el paquete ‘jtools’ que nos da la opción summ(modelo) como la veremos a continuación. (La opción con R Base es llamar el resultado con ‘summary(model)’.
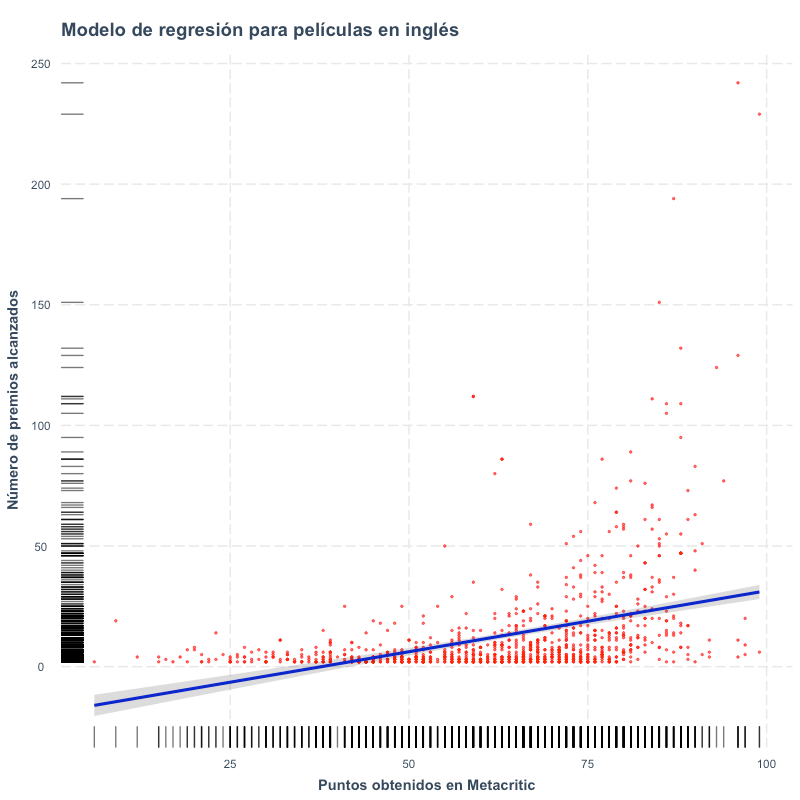
Resultados de un modelo de regresión que calcula el efecto del puntaje en Metacritic sobre el número de premios recibidos para películas en inglés disponibles en la plataforma Netflix.
La opción ‘summ(modelo)’ nos ofrece una vista más resumida de los resultados de la regresión. En primer lugar, vemos que el coeficiente del puntaje en Metacritic tiene un efecto positivo que es estadísticamente significativo sobre el número de premios que una película obtiene. El modelo cuenta con una R2 ajustada de 0.15, por lo que, si bien no es el modelo con el mejor ajuste, nos permite explicar el 15% de la varianza de los datos con los que contamos. Cabe señalar que en las exploraciones previas, ninguna otra medida de la crítica (Hiddem Gems Score, Rotten Tomatoes, IMdB Score) obtenían una correlación tan alta como el puntaje en Metacritic.
Como paso adicional, hemos decidido hacer una exploración gráfica de nuestra línea de regresión con ‘jtools’. Aunque la gráfica de correlación ya nos ofrece la visualización, hemos decidido ofrecer esta visualización adicional.
library(jtools)
premios <- metapremios$`Awards Received`
puntaje <- metapremios$`Metacritic Score`
fit <- lm(premios~puntaje)
summ(fit)
effect_plot(fit, pred = “puntaje”, interval = TRUE, plot.points = FALSE, rug=TRUE,
partial.residuals = TRUE,
point.size=0.5,
main.title = “Modelo de regresión para películas en inglés”,
x.label = “Puntos obtenidos en Metacritic”,
y.label = “Número de premios alcanzados”,
colors = “blue2”,
point.color= “red”)
Gráfico de dispersión del modelo de regresión para películas en inglés disponibles en la plataforma Netflix. El puntaje obtenido en Metacritic tiene un efecto en el número de premios alcanzados.
Discusión
Resulta difícil estimar qué película recibirá una mayor cantidad de premios únicamente tomando en cuenta la percepción que la crítica ofrece. Metacritic es un espacio para que usuarios valoren aquellos filmes que más les complacieron, la plataforma permite no solo colocar un número a las cintas sino también ofrecer una reseña. En este sentido, como plataforma social, sintetiza parte del sentimiento que las audiencias tienen en torno a una producción cinematográfica en particular y a la industria del cine en general.
En ese sentido, el puntaje en Metacritic nos ha servido como una variable de aproximación (proxy) a un elemento que puede tener impacto en el éxito final, medido en número de premios, que tiene una película.
El modelo de regresión, con su R2=0.15 nos lleva en la línea correcta al poner a prueba el efecto de una variable que podría explicar, en parte, el éxito de una producción cinematográfica. En este caso, hemos limitado el cálculo a cintas en habla inglesa que se encuentran en una plataforma, Netflix, por lo que no sabemos nada de aquellas cintas fuera de la plataforma, pero creemos que esta muestra nos da pistas del fenómeno.
Otra caución a tomar en cuenta es que un modelo de regresión linear puede no ser tan indicado para evaluar el efecto que la crítica tiene en las películas. Es posible que, si exploramos la asociación entre estas dos variables tomando en cuenta el género del filme, obtengamos resultados más robustos para cierto tipo de filmes (drama, comedia, acción, etc.), por lo que necesitamos seguir explorando los datos integrando variables de otro tipo (categóricas) con un modelo ajustado a las mismas.
Conclusiones
Este ejercicio ha buscado poner a prueba la idea de que el peso de la crítica tiene cierto efecto en el reconocimiento que un filme logra. Así, hemos visto que la calificación que las audiencias ofrecen a una película está asociado positivamente con el número de premios que ésta recibe.
Al calcular un modelo de regresión, hemos podido estimar el efecto que buenas calificaciones llegan a tener en producciones cinematográficas. Hemos usado una base disponible y que cuenta con cintas disponibles en una plataforma de VOD. De contar con un mayor número de datos, es posible que podamos confirmar esta premisa y, si estimamos modelos que puedan integrar variables categóricas, también es posible que podamos discernir el efecto entre distintos tipos de películas.
De momento, hemos logrado explorar la posibilidad de bases de datos de este tipo en el ánimo de utilizar herramientas de estadística y visualización de datos para estimar analíticas culturales, un área en la que creemos que es necesario diseñar aproximaciones sistemáticas que nos permitan construir una mejor comprensión de los fenómenos culturales contemporáneos.
Publicado originalmente en Medium el 17 de marzo de 2020
La pandemia por COVID-19, la variante de coronavirus que surgió en Wuhan, China a finales de 2019, ha inundado la conversación digital. En México, la producción de mensajes en torno al “coronavirus” ha mantenido una serie de hashtags entre los “trending topics” de los últimos días debido, principalmente, a las noticias de nuevos casos y a las medidas implementadas por las autoridades con miras a contener el contagio.
El 11 de marzo, la OMS declaró el brote de COVID-19 como una pandemia y en México el tema colocó a dicha palabra, “pandemia” como uno de los TT durante aquella jornada. En México, según la estimación del encargado de la crisis sanitaria, el subsecretario de Salud, Hugo López-Gatell, nos esperan 12 semanas con este tema. Mientras distintas medidas se toman en el país (al igual que en otros países) y el número de pacientes en México pasó de 53 a 82 el día 17 de marzo, las y los usuarios de Twitter mantienen activa la conversación respecto al tema.
A partir de dos extracciones de datos de la red social Twitter, buscamos evaluar dos cosas: ¿hacia quién se dirigen las interacciones en el marco de la contingencia por COVID-19? y por otra parte, ¿entre quiénes se entrelaza la conversación digital?
Lo que sigue a continuación son visualizaciones e interpretaciones muy someras de datos, exploratorias en primer lugar pero que buscan hacer un poco de sentido a cómo los usuarios usan las redes en momentos de incertidumbre.
Información, ansiedad y duda de alta exposición
A pesar de la existencia de canales institucionales de información (conferencias de prensa diarias y emisión de boletines informativos), se han dado fenómenos como las compras de pánico en algunos lugares de México o difusión de noticias falsas, tanto por medios como WhatsApp como desde las cuentas personales de periodistas.
Ante ello, la primera pregunta que nos surgió es hacia quién se está dirigiendo la conversación digital en redes sociales, en particular Twitter, en el marco de la crisis por COVID-19 o coronavirus en México.
Dado que existen múltiples hashtags en uso para referirse a la pandemia (#covid19, #covid-19, #covid19mx, entre otras variantes) decidimos dejar de lado la idea de extraer mensajes mediante un hashtag. En su lugar usamos una palabra clave, simple pero presente en casi todos lados: “coronavirus”.
La siguiente dificultad era el hecho de que esta palabra está presente tanto en los mensajes en español (en toda Latinoamérica) como en inglés en el resto del mundo. Para tratar de filtrar lo más posible la búsqueda, decidimos captar los mensajes geolocalizados alrededor del centro de México.
Adicionalmente, decidimos dejar fuera los retweets de la primera muestra. La premisa era sencilla: en un primer momento, no nos interesan las interacciones como quién está siendo referido en los mensajes que hablan del tema.
A partir de este triple criterio (palabra clave + geolocalización + mensajes únicos) realizamos una extracción de publicaciones de Twitter mediante R Studio. El resultado fueron 108 mil mensajes únicos publicados entre las 20 horas del 12 y las 11 horas del 17 de marzo, aproximadamente.
Extracción de mensajes únicos en Twitter
Llamamos “mensajes únicos” a los que se visualizan a continuación, ya que descartamos de la extracción aquellos que son retweets y captamos solo publicaciones independientes entre sí. Esto reducirá la cantidad de relaciones entre el total de los usuarios obtenidos, pero nos permitirá observar a quién se dirigen (si acaso) sus mensajes en forma de menciones y replies.
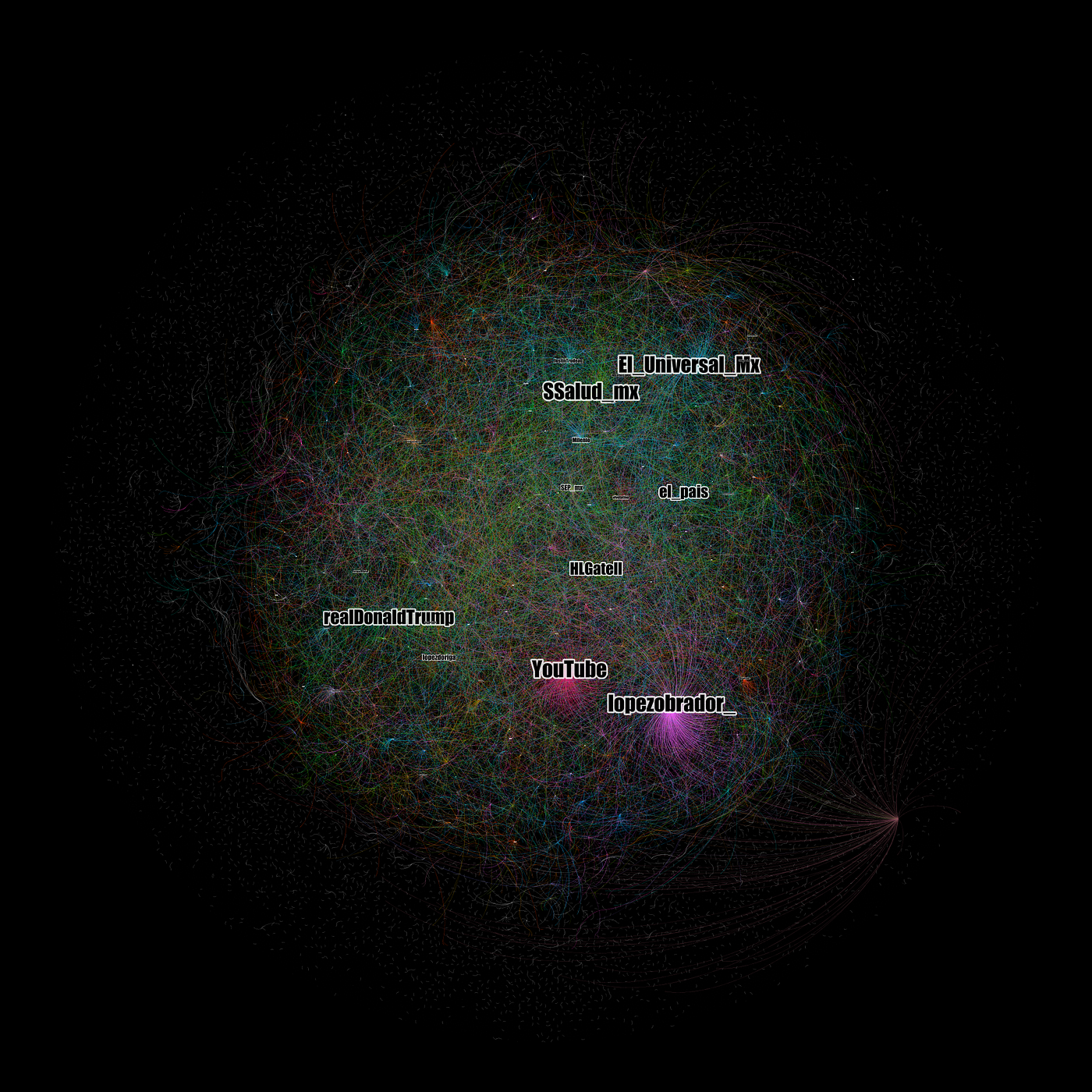
Grafo 1. Red usuario-a-usuario a partir de 108 mil mensajes únicos publicados en Twitter (18/03/2020) geolocalizados en México a partir de la palabra clave “coronavirus”. La visualización se construyó mediante el algoritmo Force Atlas 2 de Gephi, las etiquetas de nodos destacan aquellos con mayor grado de entrada con pesos.
La red U2U está conformada por 56,821 nodos y 26,450 aristas. Al haber descartado los retweets es de esperar contar con una red “menos conectada”. En el Grafo 1 se visualizan los nodos con mayor grado de entrada. Son usuarios que recibieron mayor número de menciones o respuestas en la red. Además de la cuenta del presidente de México, Andrés Manuel López Obrador (@lopezobrador_) se encuentran la cuenta oficial de la Secretaría de Salud y la del subsecretario de esa dependencia, Hugo López-Gatell.
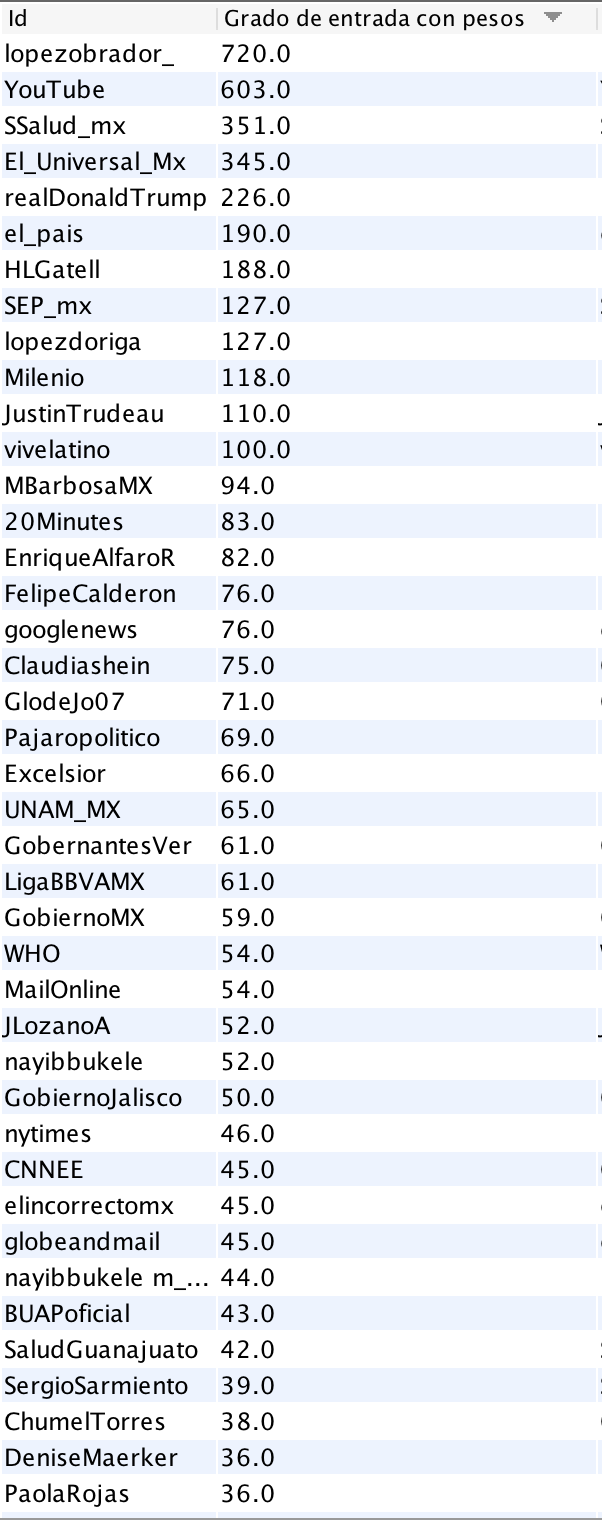
La cuenta de dos medios, El Universal y El País, se encuentran entre los nodos con mayor número de relaciones de entrada. También se encuentra el servicio de video YouTube y la cuenta del presidente de Estados Unidos, Donald Trump (@realDonaldTrump). Otras cuentas que se volvieron centrales fueron la del periodista Joaquín López Dóriga, la del ministro canadiense Justin Trudeau, y la cuenta del festival musical Vive Latino que se realizó el fin de semana previo pese a las críticas y dudas en medio de la crisis de COVID19. Para tener una mejor idea de aquellos nodos más centrales (por in-degree), los ubicamos en la tabla que nos ofrece Gephi.
Tabla 1. Nodos con mayor grado de entrada en el Grafo 1.
Entre los usuarios hacia los que más se dirigieron mensajes en la muestra de mensajes únicos se encuentran periodistas, autoridades y medios de comunicación. Al haber descartado los retweets de la extracción, solo captamos los mensajes dirigidos y menciones hacia estos usuarios. No exploramos en el campo de “text” de las publicaciones por lo que no aventuramos el sentido (positivo/negativo) de las publicaciones.
Una posible forma de interpretar este patrón podría ser la siguiente: al observar mensajes únicos (descartando RTs) en Twitter en torno al tema de la pandemia por coronavirus en México, vemos que gran cantidad de los contenidos se dirigen a autoridades, personajes políticos y medios. Así, es posible que los usuarios estén dirigiendo dudas o reclamos a esos nodos más centrales.
El método de extracción que elegimos en esta primera fase nos da redes más desconectadas. Una prueba de ello es observar de nuevo el Grafo 2 pero destacando los nodos por grado de salida. Así vemos una gran cantidad de nodos desconectados del resto de la red que “orbitan” a aquellos sectores más conectados. Estos “satélites” son usuarios que, aun cuando usaron la palabra clave de nuestro criterio de búsqueda, no mencionaron ni respondieron a otros usuarios en esta muestra.
Grafo 2. Red usuario-a-usuario, los nodos se destaca por su grado de salida.
Extracción de mensajes incluyendo retweets
Cuando cambiamos el método de extracción y aceptamos captar los retweets tendemos a obtener una red más conectada. Los retweets parecen expresar cierto grado de connivencia con el mensaje del autor. Esta relación positiva entre usuarios se suma a las menciones y respuestas, que pueden tener otra cualidad.
Sin embargo, lo que sí parece representarse de manera más coherente son las “comunidades” de usuarios que se forman en torno a ciertos temas o a otros usuarios. La ventaja de incluir los retweets parece ser la de dar mayor cohesión a aquellos usuarios que comparten más “espacio digital” en una muestra de tweets dada.
El Grafo 3 representa las relaciones de usuario-a-usuario para una muestra de 107 mil mensajes en la red social Twitter, publicados entre las 20 horas del 16 y 11 horas del 17 de marzo, aproximadamente. El grafo resultante cuenta con 72,258 nodos y 94,037 aristas. Es notable que abarca menos tiempo, esto debido a que absorbimos el impacto de los retweets.
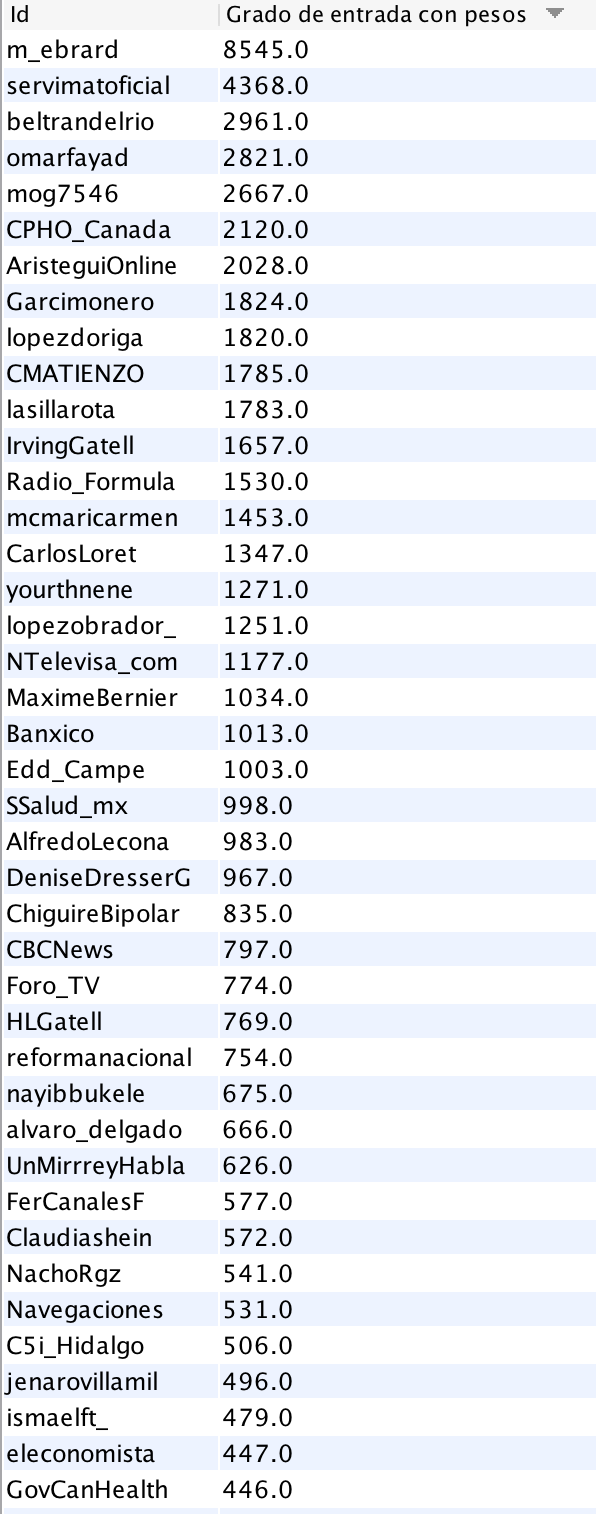
Grafo 3. Red de usuario-a-usuario a partir de 107 mil mensajes en el servicio Twitter, geolocalizados en México y a partir de la palabra clave “coronavirus”. Las etiquetas de nodo más grandes expresan a los usuarios con mayor grado de entrada.
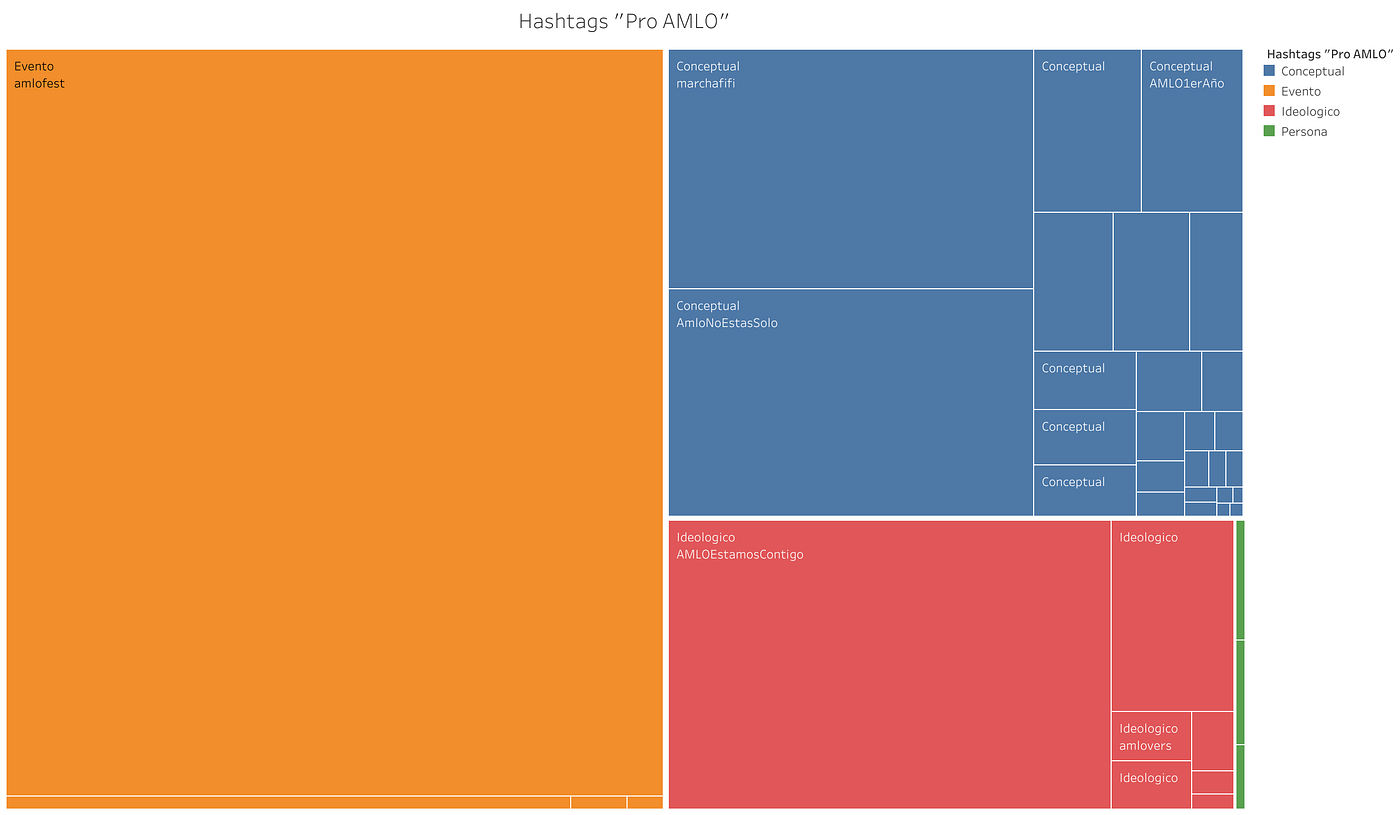
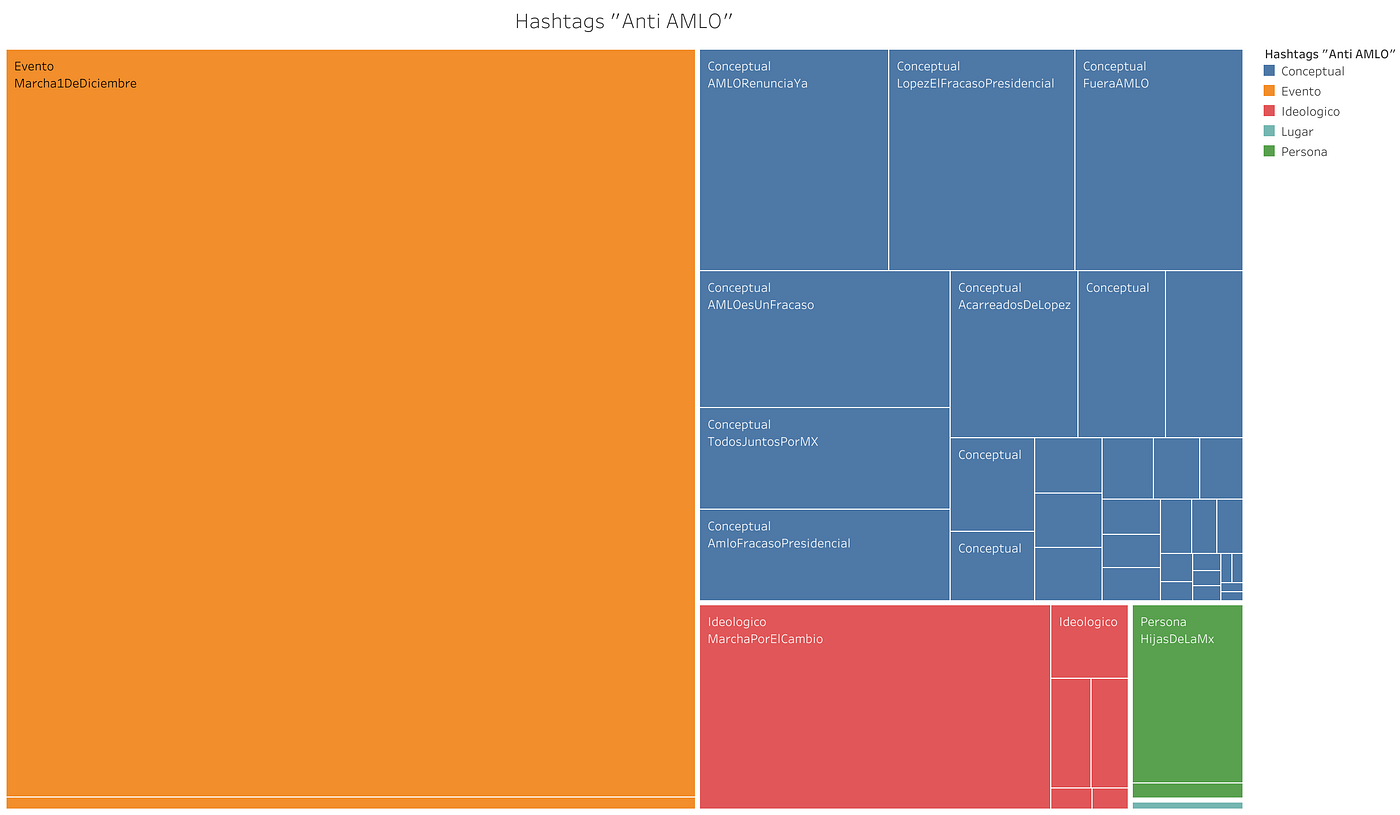
El patrón que muestra el nuevo Grafo 3 al incluirse los RTs es muy distinto al del primer grafo. En primer lugar, podemos notar que a pesar de que existe un gran número de comunidades (en una publicación anteriores notamos la polaridad en la discusión digital cuando usábamos un criterio de búsqueda por hashtag: Redes a favor y en contra de AMLO en México), la vinculación entre ellas es de “poca fuerza” y mantiene a los islotes de usuarios entremezclados en algunas zonas y separados en islas en otras. La lista de usuarios más centrales por grado de entrada es ilustrativa en este sentido.
Tabla 2. Usuarios con mayor grado de entrada en el Grafo 3 que incluye relaciones de retweet.
Aunque siguen apareciendo autoridades y periodistas, a la lista se unen youtubers, medios alternativos e incluso cuentas “de humor”.
Una forma de interpretar este patrón es que, además de la información oficial en torno al tema que aquí nos ocupa, la pandemia por coronavirus presente en México, otras formas de interpretar el fenómeno están activas en la conversación además de la información oficial y la interpelación entre actores políticos, que muchas veces ocupan gran parte de los análisis.
Otra cosa a considerar es que el método de extracción nos ofreció un panorama más heterogéneo en torno al tema del coronavirus. Creemos que en ocasiones, el uso de hashtags para generar grafos nos impide ver a ciertos usuarios. Encontrar la manera de salvar estos sesgos no es fácil ni creemos aquí haber logrado algo por el estilo. Pero sí creemos que utilizar una palabra clave y la geolocalización de mensajes en lugar de una etiqueta cambia la forma de los patrones encontrados en los grafos. Para el caso que aquí expusimos, la poca conectividad interna de la red nos resultó llamativa y expresiva de una heterogeneidad en la conversación. Por ejemplo, cuando sometimos el grafo a un filtro de conectividad k-core (k=2) nos quedamos con apenas el 25% por ciento de los nodos y el 49% de las aristas. Cuando elevamos k=3 nos quedó poco más del 9% de los nodos y 27.5% de las aristas. Es decir, una gran sección del grafo está muy poco conectada entre sí y al resto de los nodos, a pesar de captar las relaciones de retweet.
Posibles consideraciones al momento de analizar datos de Twitter
Como se puede adivinar, esta exploración de datos está lejos de proponer conclusiones. Pero sí algunas consideraciones al momento de analizar datos extraídos de Twitter.
La primera es que los datos con que trabajamos, como con cualquier otra estrategia de investigación, están lejos de ser precisos. Aunque usamos operadores para geolocalizar mensajes de Twitter esperando obtener solo publicaciones de México, estuvimos lejos de lograr el objetivo. Algunas publicaciones de usuarios fuera del país cayeron en la muestra.
Otra observación es que, al descartar un tipo de las relaciones posibles entre usuarios (en la primera muestra, el retweet) los patrones que se nos presentan son muy distintos a cuando sí la tomamos en cuenta. (Sin contar el sesgo temporal que se nos podría presentar: en la primera muestra, captamos más días que en la segunda) Esto implica que podemos cambiar las preguntas que hacemos a los datos a partir de cómo integramos o dejamos de lado ciertos tipos de relaciones susceptibles de observarse.
Finalmente, que dando estas pequeñas vueltas de tuerca, podemos pasar de un problema a otro muy distinto. Aquí apenas quisimos sugerir hacia dónde y quién se está dirigiendo la conversación digital en el tema del coronavirus y cómo cambia la perspectiva si se integra o descarta un tipo de relación posible. Mientras reflexionamos al respecto, quizá se nos ocurran nuevas preguntas qué formular a los datos.
El presidente Andrés Manuel López Obrador presentó su informe con motivo al primer año de gobierno. En el marco de su mensaje, aseguró haber cumplido 89 de 100 compromisos establecidos como metas de su primer año de gestión. Sin embargo, su informe se presenta ensombrecido por el aumento de la violencia del crimen organizado que ha dejado 33 mil personas asesinadas en lo que va de su administración, la paralización del crecimiento económico y duras batallas políticas como la designación de la titular de la Comisión Nacional de Derechos Humanos, las idas y venidas con el gobierno estadounidense de Donald Trump, la movilización de activistas como la familia LeBarón y Javier Sicilia, y la controversia por el asilo político otorgado al presidente de Bolivia, Evo Morales.
Prácticamente, todas las coyunturas del “primer gobierno de izquierda mexicano” han sido acompañadas por explosiones de activación digital en servicios de redes sociales, en especial, Twitter. Diversos analistas han señalado la presencia de redes tanto a favor como en contra del presidente López Obrador que han participado en un intenso debate con signos de polarización.
Las redes sociodigitales han sido el escenario en el que múltiples voces se han hecho escuchar, las usuarias y usuarios han construido “paisajes” y foros de los que se ha apropiado para las más diversas movilizaciones de reclamos y discursos. Tan sólo en el último año, eventos tales como el #MeToo mexicano, las coyunturas producidas por hechos violentos como el ataque en Minatitlán (Signa Lab) o las propias elecciones de 2018 con el esfuerzo de #VerificadoMX han dejado constancia de los espacios de imaginación, posibilidad y disputa que se generan en “las redes”.
Sin embargo, también se han hecho visibles nuevas lógicas que parecen buscar la desapropiación de estos nuevos espacios.
De ahí que cada vez sea más necesario ver con precaución lo que ocurre en la “esfera digital” para no tomar las producciones culturales de estos espacios como si fueran un simple reflejo del estado de ánimo de la ciudadanía. Hay solapamientos entre ambos espacios, el digital y “analógico”, pero la construcción de las distinciones requiere cierto distanciamiento.
El laboratorio de investigación de ITESO Guadalajada, Signa Lab, señaló en un breve informe algo que puede parecer obvio pero en lo que cabe la pena detenerse: “internet no es una sustitución del espacio público ni de las prácticas políticas, sino un escenario de rearticulación de los repertorios comunicativos y políticos” y las nuevas dinámicas producidos desde y hacia el poder “constituye una muestra de cómo la lucha por los regímenes de verdad y la «producción» de lo político en los entornos digitales ha entrado en una fase marcada por los procesos de automatización”.
La discusión sobre la presencia de automatismos y bots en la discusión política digital es importante pero, creemos, no lo es todo. Lo que la discusión digital parece presentarnos son aparentes “cajas de resonancia” que podrían interpretarse como polarización. Sin embargo, ¿a qué grado existe polarización sin diálogo? ¿Qué vasos comunican las líneas del debate digital? O, si no llegamos a precisar estas cuestiones, valdría quizá la pena saber ¿de qué están hablando esas esferas distantes pero necesariamente conectadas que se juegan el todo por el todo en un “con nosotr*s o con ell*s”?
AMLO: Primer año, informe y marchas
Para tratar de ensayar una respuesta a esta última pregunta hemos realizado una extracción de mensajes de la red social Twitter durante el día 1 de diciembre de 2019. La extracción se realizó de las 12:00 a las 18:00 horas obteniéndose un total de 115,632 tweets. El criterio de selección fueron dos etiquetas o hashtags “antagónicos” en la conversación digital: #amlofest y #marcha1dediciembre. Las etiquetas fueron elegidas por ser las que ocuparon los primeros lugares en los Trending Topics de México durante la hora posterior al inicio del informe por el primer año de gobierno de Andrés Manuel López Obrador y la marcha realizada por opositores que partió del Ángel de la Independencia al Monumento a la Revolución, ambos eventos, en la Ciudad de México. (Los tweets fueron recuperados mediante R Studio utilizando la librería “rtweet”, las visualizaciones fueron realizadas con la paquetería Gephi. Todos los grafos recibieron el mismo tratamiento: el algoritmo de distribución fue Force Atlas 2, las etiquetas tienen tamaños proporcionales para medidas de grado con pesos).
El Grafo 1 visualiza las relaciones entre usuarios (red usuario-a-usuario — menciones, retuits, favoritos — ) para los mensajes que conforman la muestra. Los nodos se encuentran escalados por grado de entrada por lo que las etiquetas de nodo más grandes muestran a los usuarios a los que se dirigieron mayor número de mensajes en la muestra. La red cuenta con 33,729 nodos y 115,590 aristas (Av. Degree: 3.42, Av. Path Lengh: 7.26). El cálculo de modularidad dio como resultado 1,432 comunidades (Res: 1, Modularity: 0.46).
Grafo 1. Red de usuario a usuario para las etiquetas #amlofest y #marcha1dediciembre. Nodos: 32,729. Aristas: 115,590. Los nodos están representados por mayor grado de entrada con pesos.
Básicamente, se forman dos grandes comunidades. La azul, en la que la cuenta @lopezobrador_ cuenta con el mayor grado de entrada, representaría una comunidad “pro-AMLO” mientras que la comunidad naranja representaría la red “Anti AMLO” en la que, además de la cuenta del medio El Universal, otras dos cuentas presentan alto grado de entrada. Se trata de las cuentas @FerBetancourt09 y @GlodeJo07. Estas cuentas aglomeran un gran número de retweets y favoritos. A continuación se muestran dos de los mensajes con mayor número de interacciones en la red.
Andan escribiendo por todos lados que la “marcha es pedorra”, que “puro pendejo va”, que “junta mas gente un perro atropellado”. A ver,si tan pedorra es la marcha ¿por qué les preocupa tanto que andan desesperados por desacreditarla? La oposición ya se unió ❤️#Marcha1DeDiciembre
La sola presencia de usuarios con alto nivel de entrada en una red, sea esta a favor o en contra de un personaje, no otorga por si misma evidencia de automatismos o coordinación. Para ello, sería necesario analizar más a detalle a los usuarios que interactúan en sendas redes. No es ese el objetivo de este pequeño ensayo. Sino el contenido de los discursos circulantes “entre” las comunidades.
Para ello, el siguiente paso fue realizar un grafo de los hashtags usados por los usuarios (usuario-a-hashtag). El resultado fue una red con 20.924 nodos y 54,427 aristas (Av. Degree: 2.6; Av. Path Lenght: 1) cuyo cálculo de modularidad dio como resultado 3,998 comunidades.
Una forma de interpretar lo anterior podría ser la siguiente: si bien hemos extraído mensajes a partir de dos etiquetas o palabras clave, los usuarios utilizan una gran variedad de hashtags en su producción; no obstante ello, es posible que ciertas etiquetas tiendan a “agruparse” y son esos pequeños clusters de palabras clave las que nos dan una pista sobre la cualidad del discurso que cada red estaría movilizando.
El Grafo 2 muestra estas relaciones. Las etiquetas tienen tamaños proporcionales para grado con pesos. Aunque ahora parece haber más comunidades en juego, hay dos principales que atraen nuestra atención.
Grafo 2. Red de usuarios a hashtags. Los etiquetas de nodo con mayor tamaño expresan su grado con pesos dentro de la red.
En la comunidad azul (ahora “Anti AMLO”) la etiqueta principal es la que guió parte de nuestra búsqueda, #marcha1dediciembre, pero a esta se asocian con cierta importancia hashtags tales como #marchaporelcambio, #lopezelfracasopresidencial y #amlorenunciaya, entre otras.
En la comunidad roja (“Pro AMLO”) el peso de las etiquetas está más distribuido no solo entre la principal, #AMLOfest, sino que le sigue #AMLOnoestassolo, #AMLOestamoscontigo y #marchafifi. En cuanto a la segunda y tercera, tienen cierta similitud con las que se han presentado en otras coyunturas impulsadas por la denominada RedAMLOve (Signa Lab).
Para algunos autores, el uso de hashtags forma parte de la estrategia de estas redes digitales para visibilizar sus mensajes, aglomerar a los adherentes y establecer las pautas del discurso que producen (Blevins et al, 2019) y es de esperarse que entre las etiquetas se dé cierto grado de homofilia (Xu y Zhou, 2020) o en nuestros términos, que la afinidad entre los miembros de una red dé como resultado un uso más “coordinado” de las etiquetas.
Es en las relaciones entre las etiquetas donde creemos que se dan algunas pistas de cómo se da el diálogo, si alguno, entre las redes de activación digital, en este caso, a favor y en contra de un tema o personaje político.
Mañana se cumple un año del inicio de una transformación del país que debe iniciar c un cambio personal. Al zócalo #Amlofest. Por un trabajo a favor del todo.
Redes antagónicas, esferas desconectadas: el debate sin diálogo en torno a AMLO
El último paso que seguimos fue graficar las relaciones entre etiquetas. El grafo por sí mismo no nos da mucha más información, pero es necesario visualizarlo para ver cómo se distribuye el discurso digital cuando solo de hashtags se trata.
El Grafo 3 contiene 1,373 hashtags representados por nodos entre los cuales existen 2,943 relaciones o aristas (Av. Degree: 4.3). El cálculo de modularidad (0.45) dio como resultado 56 comunidades.
Grafo 3. Relaciones entre hashtags que conforman la muestra. Nodos: 1,373. Aristas: 2,943.
A partir de este grafo se realizó un sub-selección de etiquetas. Para ello, se utilizó el filtro de conectividad K-Core (k=5) (El filtro de conectividad K-Core es una de las opciones de filtrado que ofrece el software Gephi y permite obtener los nodos más conectados a la red. A mayor profundidad del filtro, menos nodos quedan en el grafo, pero manteniéndose siempre los que cuentan con mayor número de relaciones. Así, el filtrado nos permite “ver” a aquellos nodos que “sostienen” la red). El resultado dejó un total de 146 nodos (que representan el 10.6% del total) y 1,026 relaciones entre los mismos (34.86%).
Lo que este tipo de filtro deja ver, intuitivamente, es que solo 10% de los hashtags están presentes en más de una tercera parte de las relaciones. Es decir, obtenemos las etiquetas más utilizadas por los usuarios pero, a la vez, las más relacionadas entre sí.
Una vez obtenida esta lista de etiquetas, hemos decidido categorizarla. Para ello, partimos de dos categorías propuestas por Blevins et. al (2019) quienes señalan que los hashtags suelen representar ya sea la posición que toman los usuarios o la interpretación de estos sobre los eventos con los que entran en relación. Así, el primer tipo de hashtags serían marcadores ideológicos mientras que los segundos, representan el grupo de marcadores conceptuales.
Adicionalmente, al estudiar la lista de hashtags hemos decidido añadir nuevas categorías: primero, separamos aquellas etiquetas que refieren al Evento “en sí”, y que representan nuestros criterios de búsqueda; separamos también las etiquetas que hacían referencias a lugares, a personas, a fechas o momentos del día y una última categoría que denominamos “Topic” para aquellos temas que se salían de la discusión o que referían a temas específicos.
Distribución de los hashtags utilizados por los usuarios que conforman la muestra. El tamaño de los cuadros de hashtag expresa su grado con pesos dentro de la red HT2HT.
Las etiquetas de Evento (15) representan el 10.3% del total de hashtags utilizados. Las que conforman la mayoría del discurso son los marcadores Conceptuales (70 hashtags, 48% del total). El resto son los marcadores Ideológicos (13 HT’s, 8.9%), de Lugar (20 HT’s. 13.7%), de Tópico (15 HTs, 10.3%), de Persona (10 HTs, 6.8%) y Tiempo (3 HTs, 2%).
Si seguimos lo hasta aquí expuesto, la mayor parte de los mensajes que conforman la muestra, al utilizar marcadores conceptuales, estarían produciendo un discurso que busca interpretar o “enmarcar” la coyuntura política de la que están participando.
Por “enmarcamiento” nos referimos a los marcos interpretativos a partir de los cuales un grupo busca hacer sentido tanto de su acción como de los eventos, y esta definición de intereses se da en contraposición a otros grupos (Treré, 2015).
Lo anterior nos parece importante porque, lo que intenta ensayar esta respuesta es: que dado que parecen existir dos esferas en discusión, luchando por la definición del espacio político digital, la forma en que buscan enmarcar (o dar significado a) los eventos importa por lo que propone tanto a sus adherentes como a los públicos de esta conversación.
¿Cómo proponen estas redes antagónicas el discurso digital? Para tratar de hallar pistas al respecto hemos vuelto a categorizar las etiquetas obtenidas, esta vez, definiéndolas como parte de un discurso “Anti AMLO” y uno “Pro AMLO”. Esta decisión, un tanto arbitraria, solo intenta seguir la línea que los mensajes sugieren. No es una definición normativa como guiada a la vez por los datos y por el criterio analítico que aquí hemos seguido.
Del total de etiquetas, 47 se clasificaron como “Anti AMLO” (32.2%) mientras que 48 cayeron en la categoría “Pro AMLO” (32.8%). Un total de 9 etiquetas (6.16%) fueron calificadas como “Ambiguas” pues, al revisar los mensajes parecían usadas de forma indistinta por sendos grupos mientras que 42 (28.7%) no calificaron en ninguna de las categorías.
Distribución de los hashtags utilizados en la conversación por “orientación” ya sea a favor o en contra de Andrés Manuel López Obrador.
El discurso “Pro AMLO”
La tabla mostrada a continuación muestra la distribución de las etiquetas “Pro AMLO”. Las más utilizadas de las 48 etiquetas fueron las Conceptuales (30 HTs, 62.5% del total de este grupo). El discurso digital del grupo a favor de López Obrador dedica parte de sus esfuerzos hacia la #marchafifí, forma en la que designa a la movilización opositora que se realizó el 1 de diciembre del Ángel de la Independencia al Monumento a la Revolución. Es una etiqueta de directo antagonismo al grupo adversario. Pero le siguen en importancia hastags tales como #AMLONoEstasSolo, #GobiernoDelPueblo y #EsUnHonorEstarConObrador, entre otros. El enmarcamiento que parecen proponer es a la vez de contraposición con el grupo adversario y de unidad en torno a la imagen del presidente de la república. De ahí que otras etiquetas asociadas en esta parte del discurso sean #OposicionMoralmenteDerrotada entre otros.
La identidad del grupo se engloba en torno a etiquetas como #amlovers, #todosalzocaloconAMLO, #AMLOestamoscontigo (esta última, aunque similar a la conceptual #AMLONoEstasSolo, se colocó en este grupo por la definición de la primera persona con la que se construyó la etiqueta).
Distribución y categorías de los hashtags utilizados en la conversación por la red “Pro AMLO”. El tamaño de los recuadros expresa su grado con pesos dentro de la red.
Lo que parece proponer, de manera global, la red “Pro AMLO” es la existencia de un sector que apoya incondicionalmente al personaje político que engloba la discusión. Interpretan y proponen la discusión desde una posición superior a la de la oposición y de cohesión en torno a la imagen de López Obrador.
El discurso “Anti AMLO”
La siguiente tabla muestra la distribución de las etiquetas “Anti AMLO”. Las más utilizadas (34 HTs, 72.3% del total del grupo) son de nuevo, Conceptuales. En el discurso digital contra López Obrador aparece como más central #AMLORenunciaYA, acompañada de etiquetas como #LopezElFracasoPresidencial, #FueraAMLO, #AMLOEsUnFracaso, entre otras del mismo tipo. La estrategia de enmarcamiento del grupo opositor parece proponer la desaprobación de la gestión presidencial y la demanda de renuncia del gobierno en curso. Pero también hay etiquetas que buscan oponerse a la otra red, del mismo modo que aquella propuso #marchafifí, en el discurso “Anti AMLO” hay etiquetas como: #AcarreadosDeLopez, #LosDelZocaloSonAcarreados. Sin embargo, el discurso antagónico hacia el otro grupo no es tan central, sino que la desaprobación presidencial es el principal contenido del discurso digital de esta red.
La toma de posición de esta red se engloba en etiquetas como #MarchaPorElCambio y #OposiciónCiuadadana, e incluso #AntiAMLO, entre otras. Lo que esta sección del discurso parece proponer es su diferenciación con el grupo antagónico, pero además, la de una composición ciudadana — que implícitamente sugiere que otros grupos no lo son — bajo la cual se buscaría establecer la legitimidad de la demanda.
Distribución y categorías de los hashtags utilizados en la conversación por la red “Anti AMLO”. El tamaño de los recuadros expresa su grado con pesos dentro de la red.
En resumen, la movilización digital “Anti AMLO” no solo propone desaprobar la gestión de López Obrador sino significar su activación como legítima y ciudadana, un valor que buscarían reivindicar para aumentar la cohesión del grupo.
Activación y diálogo: el intersticio de las redes
Un problema al captar hashtags mediante extracciones de Twitter es que se vuelve difícil “ver” a aquellos usuarios que se han incrustado en el debate sin utilizar las etiquetas.
Mientras que los grupos a favor o en contra de López Obrador, en redes, parecen tener cierta cohesión (si bien pueden ser en parte producto de automatismos, no hay que subestimar la cantidad de usuarios “reales” que participan y se compromete con la discusión), más que diálogo parecen existir dos cajas de resonancia que se aíslan una a la otra, pero que no dejan de dirigirse mensajes, calificaciones y reivindicaciones.
Pero es en el intersticio que se forma entre estas dos esferas donde podría estarse dando el verdadero debate entre usuarios, el verdadero diálogo, si alguno. Quizá uno de los efectos de estas redes de activación digital en torno a las coyunturas políticas, con el uso estratégico de hashtags que tienen, es la invisibilización de los espacios de diálogo que el ambiente digital provee a los usuarios.
En contra de la hipótesis de la polarización (que no está exenta de valiosas interpretaciones del fenómeno), lo que queremos decir con esta respuesta ensayada es que, es posible que uno de los efectos de la disputa por las redes digitales sea la reducción de la densidad o el sometimiento a la gravedad de los hashtags de esos intercambios comunicativos valiosos y que no dejan de presentarse en las redes pero que se vuelven más difíciles de ver cuando el algoritmo nos conduce hacia los mensajes más virulentos a veces, y masivos casi siempre, de las redes antagónicas que se disputan el derecho a designar e interpretar el espacio político digital en el que nos encontramos.
Referencias
Blevins, J. L., Lee, J. J., McCabe, E. E., & Edgerton, E. (2019). Tweeting for social justice in #Ferguson: Affective discourse in Twitter hashtags. New Media & Society, 21(7), 1636–1653. https://doi.org/10.1177/1461444819827030
Treré, E. (2015). Reclaiming, proclaiming, and maintaining collective identity in the #YoSoy132 movement in Mexico: An examination of digital frontstage and backstage activism through social media and instant messaging platforms. Information, Communication & Society, 18(8), 901–915. https://doi.org/10.1080/1369118X.2015.1043744
Xu, S., & Zhou, A. (2020). Hashtag homophily in twitter network: Examining a controversial cause-related marketing campaign. Computers in Human Behavior, 102, 87–96. https://doi.org/10.1016/j.chb.2019.08.006