Las tecnologías de inteligencia artificial podrían conducir a un «renacimiento de la humanidad», señaló LeCun en declaraciones a la BBC
Yann LeCun, considerado uno de los «padrinos» de la IA. Foto vía Wikimedia
El pionero de la inteligencia artificial (IA), Yann LeCun, ha desestimado las preocupaciones sobre una amenaza existencial de la IA para la humanidad como algo «ridículo». Durante un evento centrado en la IA celebrado en París por Meta, donde ahora trabaja como científico jefe de IA , el profesor LeCun declaró a la BBC esta semana: «¿La IA tomará el control del mundo? No, esto es una proyección de la naturaleza humana en las máquinas».
Las declaraciones de LeCun –retomadas por DigitalTrends– contrastan con las de Geoffrey Hinton y Yoshua Bengio, con quienes recibió el Premio Turing en 2018 por avances en IA. Estos tres expertos son conocidos como «los padrinos de la IA». Hinton recientemente renunció a su cargo en Google para poder expresar libremente sus ideas sobre el desarrollo de la IA. En una reciente entrevista con CBS, al preguntársele sobre la posibilidad de que la IA «aniquile a la humanidad», Hinton respondió: «Eso no es inconcebible».
Por su parte, Bengio afirmó recientemente que aunque los sistemas de IA actuales están lejos de representar un riesgo existencial para la humanidad, es posible que las cosas se vuelvan «catastróficas» con versiones más avanzadas de la tecnología, señalando que existe «demasiada incertidumbre» sobre dónde podríamos estar con la IA en unos pocos años.
LeCun, sin embargo, parece estar más tranquilo respecto al rumbo que está tomando la IA, afirmando que los temores de que esta se apodere son exagerados. Si bien el profesor reconoció que la IA sin duda superará la inteligencia humana, afirmó que tomará años, e incluso décadas, alcanzar ese punto. Incluso en ese escenario, LeCun sostiene que la idea de que una IA superinteligente escape a nuestro control es «simplemente preposteramente ridícula», agregando que no es así como funciona nada en el mundo.
LeCun le dijo a la BBC que incluso un sistema de IA altamente avanzado «funcionaría en un centro de datos en algún lugar, con un interruptor de apagado. Y si te das cuenta de que no es seguro, simplemente no lo construyes».
El profesor considera que la IA, vista desde una perspectiva más positiva, conducirá a «un nuevo renacimiento para la humanidad», de manera similar a cómo internet o la imprenta transformaron la sociedad. Si bien la IA ha estado presente durante décadas, los avances recientes y rápidos en la tecnología la han puesto en primer plano, con herramientas poderosas como ChatGPT de OpenAI y los chatbots Bard de Google, que han ganado mucha publicidad por su impresionante capacidad para manejar datos y conversar de manera similar a los humanos.
Tanto en plataformas de redes sociales como en las tendencia de Google, de los aspirantes de MORENA, Sheinbaum y Ebrard son los que destacan
A una semana de actividad política de los aspirantes a la candidatura de la 4T, las tendencias sociodigitales dan ventaja a Claudia Sheinbaum en una carrera cerrada a solo dos competidores
Antony Flores Mérida
Las interacciones en espacios sociodigitales dan pistas que nos ayudan a interpretar la forma en que se desenvuelven determinados acontecimientos (culturales, sociales, políticos…). En este sitio se han realizado exploraciones a la discusión digital en temas como la revocación de mandato o la emergencia por COVID-19 en Twitter. Uno de los temas del momento es el proceso de selección de las candidaturas presidenciales rumbo a la elección de 2024 y en los distintos espacios sociodigitales, la selección de la candidatura de MORENA (y la 4T) ocupa los primeros lugares en la conversación.
Una pequeña muestra de videos de la red social que utilizan la palabra “corcholatas” permitió obtener datos de 440 publicaciones a las cuales se le extrajeron las etiquetas (hashtags) utilizados. La exploración se puede apreciar en la nube de palabras que se ofrece a continuación.
Los datos de esa pequeña muestra dan cuenta de cómo las etiquetas referentes a la ex Jefa de Gobierno de la ciudad de México, Claudia Sheinbaum y las del ex titular de la SRE, Marcelo Ebrard, son las más presentes en los 440 videos obtenidos en la búsqueda. No debemos pasar por alto que distintas etiquetas referentes al presidente se encuentran con una gran frecuencia en esta plataforma (AMLO, 4T, Amlovers, CorcholatasDeAMLO, LopezObrador, entre otras).
Nube de palabras elaborada a partir de las etiquetas presentes en 440 videos de la red social Tik Tok que mencionan la palabra «corcholadas».
Entre los aspirantes, el ex titular de SEGOB, Adán Augusto López, aparece en tercer lugar en menciones (aunque por cada tres menciones de Sheinbaum o Ebrard hay una de Adán Augusto). Los aspirantes Gerardo Fernández Noroña y Ricardo Monreal tienen casi el mismo nivel de menciones mientras que el aspirante del Partido Verde, Manuel Velasco, solo aparece en tres menciones en esta muestra de datos.
¿Esta tendencia está presente en otros espacios de conversación? ¿Qué nos dicen estos patrones de la contienda interna en MORENA para definir su candidatura presidencial? Para tratar de ensayar respuestas a estas cuestiones se presentan, de forma exploratoria, algunos datos de las plataformas Twitter y Google Trends.
La relación entre procesos electorales y tendencias sociodigitales
El uso de técnicas de big data como predictor de comportamientos políticos ha estado presente desde hace algunos años en el análisis de la ciencia política. Un trabajo de Prado-Román y otros (2021) cita, entre otras investigaciones, la de Christine Ma-Kellams et al. (2017) sobre el uso de Google Trends como predictor de resultados electorales. Prado-Román y sus compañeros asumen que el número de términos de búsqueda utilizados por los usuarios de plataformas sociodigitales pueden dar cuenta de la forma actual y futura de pensar y actuar de sectores importantes de la población (2021, p. 3).
Los autores del estudio citado plantean, sin embargo, una caución, y es que este tipo de «predictores» sólo funcionan en procesos democráticos y en territorios donde no hay restricciones para el uso de tecnologías digitales de comunicación interactiva. Aunque los autores ponen a prueba sus hipótesis en los casos de elecciones de Estados Unidos y Canadá, este bien podría aplicarse al contexto mexicano.
Sin embargo, no nos encontramos ante una elección presidencial sino ante el proceso interno de un grupo de partidos para elegir a la persona que, eventualmente, será su candidato/a presidencial. Por ello, más que un predictor, para esta exploración los datos pueden bien dar cuenta del ‘estado de la conversación sociodigital’ pues, a final de cuentas (y pese a que el proceso de MORENA contempla una encuesta), no estamos ante un proceso electivo convencional.
La conversación en Twitter
Durante la primera semana de actividad de las personas que buscan encabezar los “comités de defensa de la 4T” (término usado por MORENA y sus partidos aliados para quien, presumiblemente, será la persona que ostentará la candidatura presidencial), se recogieron 1.1 millones de publicaciones que mencionan los nombres o usuarios de Twitter de los cinco principales contendientes. Aunque la exploración a profundidad no se presenta en esta ocasión, sí una breve visualización de 75 mil publicaciones únicas emitidas durante los días sábado y domingo al concluir su primera semana de actividades.
Al igual que ocurre en la pequeña muestra de datos de Tik Tok, en Twitter el patrón emerge de nuevo: la aspirante Claudia Sheinbaum es la más mencionada en esta muestra de datos (casi 35 mil ocasiones, es decir, prácticamente la mitad de los datos presentes) mientras que Marcelo Ebrard tiene un 50% menos menciones que la ex Jefa de Gobierno (17.2 mil). En esta red social, Adán Augusto está más cerca del ex canciller de lo que ocurrió en Tik Tok con unas 16 mil menciones. El resto de aspirantes se encuentra, sin embargo, más lejos: Fernández Noroña logra unas 3 mil 500 y Ricardo Monreal unas 3 mil 200.
Nube de palabras elaborada a partir de una muestra de 75 mil publicaciones en Twitter que mencionan a alguno de los aspirantes a la candidatura presidencial de MORENA.
En esta muestra de datos (y a expensas de explorar la serie que abarca toda la semana), Claudia Sheinbaum es más mencionada en la plataforma Twitter superando por mucho a cualquiera de sus compañeros contendientes. Ebrard y Adán Augusto tienen una cantidad muy similar de menciones mientras que Noroña y Monreal, con cantidades muy parecidas, están muy lejos en la carrera de las menciones en Twitter.
Google Trends: una carrera presidencial entre dos aspirantes
La carrera por la candidatura de la 4T para el proceso de 2024 está, como se puede ver, muy marcada en distintas plataformas. En Google parece ocurrir algo muy similar.
Los servicios de Alphabet permiten a las personas usuarias buscar información, noticias, imágenes, videos… en toda la web. Google es uno de los servicios más usados por los mexicanos –de hecho, nuestro país es uno de los 10 que más usan los servicios de la empresa– y por ello, las tendencias de búsqueda en este servicio son un punto a considerar.
Para este ejercicio realizamos, en un navegador (Safari) y con opciones de anonimización (sin registro en cuenta de Google y con navegación privada) una consulta a Google Trends en la que colocamos los nombres de los cinco aspirantes principales a la candidatura de MORENA y sus partidos aliados.
Al colocar los nombres, en lugar de referirlos como “Tema” se eligió la opción de “Término de búsqueda” para todos los casos, para tratar de simular la conducta natural de un usuario promedio. La exploración contempla las mediciones para los últimos 30 días (con corte al 29 de junio de 2023) y se ha elegido la “Búsqueda web” como parámetro (en lugar de Noticias o cualquier otra opción).
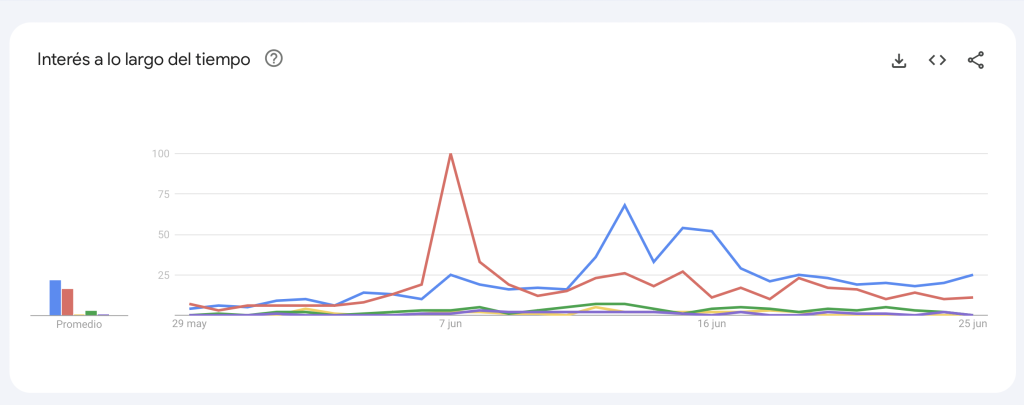
La primera gráfica muestra el “Interés a lo largo del tiempo” para el periodo seleccionado. El color azul representa a Claudia Sheinbaum, el rojo a Marcelo Ebrard, el amarillo a Adán Augusto López, el verde a Ricardo Monreal y el violeta a Fernández Noroña.
Gráfico de interés a lo largo del tiempo. Elaborado mediante Google Trends.
Al igual que ocurre en plataformas de red social, Sheinbaum parece contar con la mayor atención por parte de los usuarios y la comparte con Marcelo Ebrard.Los momentos de mayor volumen de búsquedas para cada uno coinciden (como cabe esperar) con eventos altamente mediatizados. La fecha con mayor número de búsquedas sobre la ex Jefa de Gobierno es el 13 de junio (en una tendencia que inicia varios días antes) un día después de que anunciara que pediría licencia a su cargo el 16 de junio días en los que ocupa los volúmenes más altos de búsquedas en Google. De hecho, las palabras relacionadas a su renuncia son las que ocupan los primeros lugares.
Por su parte, Marcelo Ebrard tuvo el volumen más alto de búsquedas el 7 de junio después de que anunciara que sería el primero de los aspirantes a la candidatura de la 4T en dejar su cargo y aunque mantuvo la atención de los usuarios por un par de días, el volumen de búsquedas relacionadas al ex canciller ha ido en descenso y se mantiene por debajo de las búsquedas sobre Sheinbaum Pardo. Al final del periodo observado, Claudia Sheinbaum mantiene un nivel de interés de 25 mientras que Ebrard se coloca en 11 (valores relativos a 100, el momento máximo para todo el periodo).
El resto de los aspirantes han tenido volúmenes de búsqueda muy por debajo de estos dos punteros y solo Ricardo Monreal ha llegado a niveles de atención (un máximo de 7 sobre 100) en algunos de los días previos al inicio de las giras de los aspirantes, el 19 de junio.
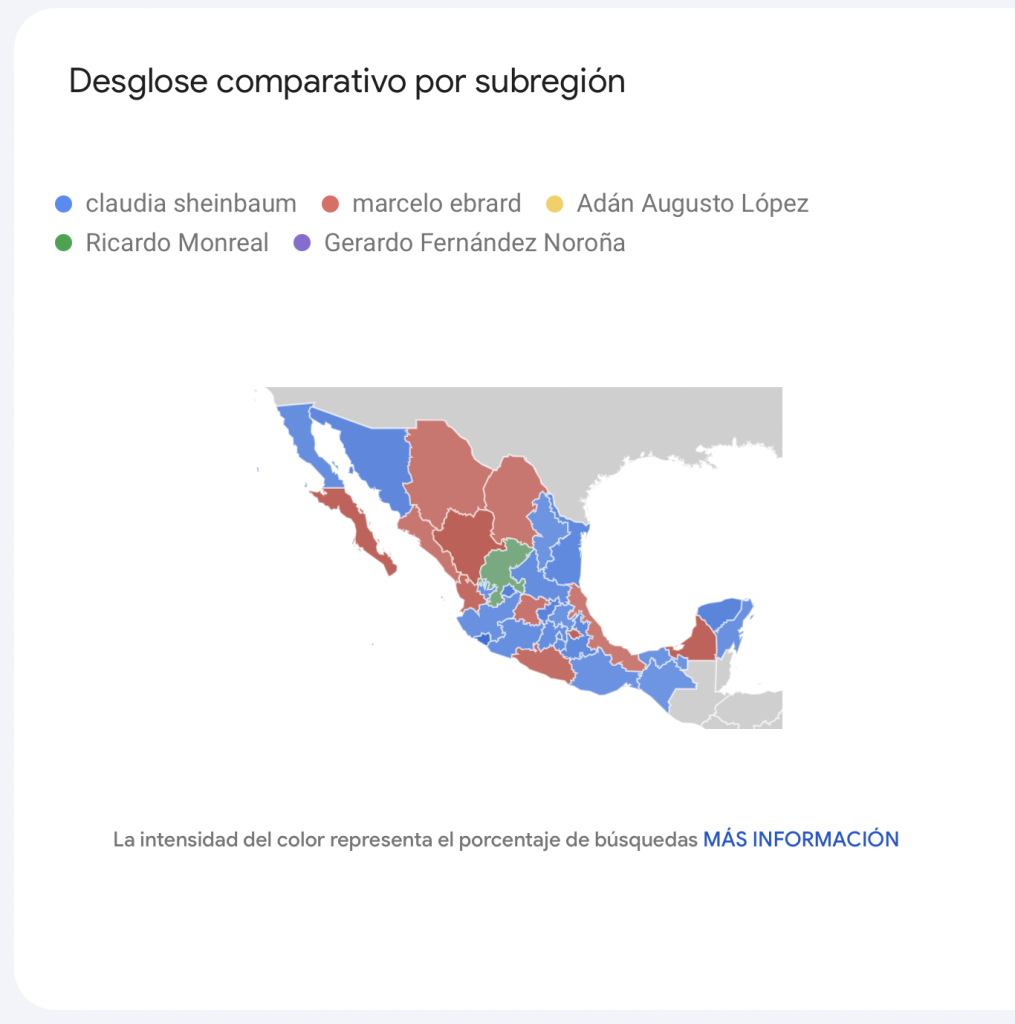
La forma en que la atención de los usuarios de Google se distribuye en el territorio también puede ser llamativa. El mapa muestra el color correspondiente a cada aspirante que se ubicó con el primer lugar en volumen de búsquedas para el periodo observado.
Comparación de las búsquedas en Google en distintas regiones del país. Elaborado con Google Trends.
Sheinbaum destaca en estados como Colima, Aguascalientes, Querétaro, Yucatán y Sonora con los niveles de atención de los buscadores más altos; Ebrard por su parte aparece con mayor presencia en búsquedas desde Durango, Tlaxcala, Campeche, Baja California Sur y Nayarit. Para la primera, la atención ha ido en aumento en Sonora pero también en Sinaloa, mientras que en el caso de Ebrard, la atención ha empezado a subir en estados del sur como Oaxaca y Guerrero, así como en algunas zonas del centro como el Estado de México.
En cuanto a Adán Augusto López, las búsquedas sobre el ex gobernador de Tabasco solo han tenido cierta densidad (aunque sin llegar a primeros lugares) en zonas del sur como Chiapas, Guerrero y Yucatán. Ricardo Monreal obtiene el primer lugar en interés en Zacatecas (de donde es originario y que gobernó de 1998 a 2004) mientras que Fernández Noroña, que no destaca en ningún estado, mantiene cierto interés en Hidalgo.
De las tendencias a los eventos políticos
¿Son las conductas de personas usuarias de las plataformas un indicador de preferencias electorales? ¿Son estas tendencias resultado o causa de la forma particular en que ciertos mensajes políticos se mediatizan? Si se han de seguir los supuestos de Prado-Román et al. (2021) y otros estudios que afirman la relación que existe entre conductas de búsqueda en línea y resultados electorales, se podría afirmar, por ejemplo, que la atención que Claudia Sheinbaum mantiene en redes como Twitter y Tik Tok así como los datos sobre búsquedas en Google permiten anticipar que esta se colocará en las preferencias de las encuestas que realizará MORENA y será, eventualmente, la candidata a la presidencia del proyecto político de la 4T.
Tan solo en el caso de Google Trends, el volumen promedio de la atención hacia Sheinbaum Pardo es cinco puntos mayor que la que se da a Marcelo Ebrard (22 vs. 17, promedio para todo el periodo). Sin embargo, en algunos periodos la diferencia entre ambos se cierra por lo que son los eventos de las giras (o campañas) de los aspirantes los que habrán de dar forma a estas tendencias.
Lo que parece más claro es que la competencia interna de MORENA se definirá entre estos dos personajes pues el resto (incluido el ex titular de SEGOB, Adán Augusto López) no cuentan con suficiente atención por parte de los usuarios en términos generales y solo logran cierta tracción en algunos estados, aunque siempre la comparten con los dos punteros.
Luego de una semana de activismo electoral, las tendencias pues, parecen definidas hacia dos aspirantes. Aunque aún falta tiempo de giras de los aspirantes (o asambleas, como las define MORENA) hasta finales de agosto y la encuesta no se realizará sino en los días posteriores a esta actividad, si alguna sorpresa depara el proceso interno de la 4T, ésta no debería tardar en presentarse.
REFERENCIAS
Ma-Kellams, Christine & Bishop, Brianna & Zhang, Mei & Villagrana, Brian. (2017). Using “Big Data” Versus Alternative Measures of Aggregate Data to Predict the U.S. 2016 Presidential Election. Psychological Reports. 121. 003329411773631. 10.1177/0033294117736318.
Prado-Román, C., Gómez-Martínez, R., & Orden-Cruz, C. (2021). Google Trends as a Predictor of Presidential Elections: The United States Versus Canada. American Behavioral Scientist, 65(4), 666-680. https://doi.org/10.1177/0002764220975067
Aunque el número de personas conectadas aumenta, se mantienen las brechas de acceso en zonas rurales
La brecha digital por razón de género se ha reducido en los últimos años; la brecha entre grupos de edad se mantiene aún muy marcada: solo 47.6% de personas mayores de 55 años son usuarias
Redacción Comsocyc
El país ganó 4.5 millones de internautas y alcanzó el 78.6% de la población mayor de 6 años conectada a internet en 2022, según la Encuesta Nacional sobre Disponibilidad y Uso de Tecnologías de la Información en los Hogares (ENDUTIH) dada a conocer por el INEGI el pasado 19 de junio. Con esto, el número de personas conectadas en México llegó a 93.1 millones en 2022.
Los datos de la más reciente encuesta del Instituto Nacional de Estadística y Geografía (INEGI) da cuenta del aumento en el número de personas usuarias de internet en México, de cómo el sector joven es el más conectado y de la reducción de la brecha digital por razón de género, entre otros datos.
En cuanto a las cifras, las poblaciones más conectadas a internet son jóvenes: el 95.1% de los jóvenes entre 18 y 24 años y el 92.8% de los que se encuentran entre 12 y 17 años, son usuarios de esta tecnología. Por otra parte, entre las personas mayores de 55 años, solo el 47.6% son usuarias. Cabe destacar que pese a esta diferencia, el porcentaje de usuarios que superan los 55 años ha ido en aumento y aumentó más de 14 puntos porcentuales entre 2019 y el año pasado.
Del total de varones, el 79.3% son usuarios y entre las mujeres, este indicador alcanzó el 78.1%. Imagen vía Dall-e
Se reduce brecha digital de género y se mantiene brecha de acceso en zonas rurales
A la vez, se ha reducido la brecha digital por razón de género: en 2019, el 71.4% de todos los hombres mayores de 6 años usaban en internet mientras que, entre las mujeres, este porcentaje solo llegaba al 68.1%. El año 2022 la diferencia entre ambos grupos se redujo a 1.2% pues del total de varones, el 79.3% son usuarios y entre las mujeres, este indicador alcanzó el 78.1%.
Aunque, como indican las cifras, esta brecha se ha ido reduciendo, aún es persistente en la mayoría de los grupos de edad, con especial énfasis en personas de 55 años o más: para este grupo erario, el 49% de los hombres usan internet pero solo 46.4% de las mujeres son usuarias. El único grupo de edad en el que esta diferencia es marcada corresponde al de 45 a 54 años, donde 79.6% de las mujeres usan internet contra el 75.8% de los varones.
Sin embargo, la brecha de acceso más importante que persiste en el país es la que separa a los entornos urbanos y rurales. De acuerdo a la encuesta, el 83.8% de las personas en zonas urbanas acceden a internet pero esta cifra cae hasta el 62.3% en las zonas rurales. Esta brecha se ha ido acortando en los últimos años y de hecho, el número de usuarios en zonas rurales crece al doble de velocidad (en términos de porcentaje de la población) con respecto al aumento de usuarios en zonas urbanas.
Aunada a la brecha de acceso debe considerarse la que se revela en las prácticas: del total de usuarios, más del 30% de los ubicados en zonas urbanas realizaron compras o pagos vía internet, cifra que cae al 15 y 11 por ciento respectivamente en zonas rurales. Otras actividades como las operaciones bancarias o las ventas en línea tienen diferencias muy marcadas entre sendos grupos poblacionales.
Tiempo de uso cae en población escolar
La comunicación y el acceso a redes sociales se encuentran entre los principales usos detectados por la ENDUTIH 2022. Imagen vía Dall-e
Otras cifras llamativas son la de tiempo de uso de internet: esta práctica tuvo un aumento durante el periodo de confinamiento por COVID en los años 2020 y 2021, sin embargo, las horas promedio de uso se redujeron en 2022 marcadamente para la población en edad escolar (el grupo de 6-11 años pasó de 6.3 a 5.9 horas promedio y el grupo de 12-17 años cayó de 5.5 a 4.7 horas) y lo hizo de manera muy ligera en los grupos de edad de adultos jóvenes (el grupo de 25-34 años cayó 0.3 horas y se ubicó en 5.3 mientras el de 35-44 años disminuyó en 0.1 para ubicarse en 4.5 horas promedio).
En cuanto a los usos detectados por la encuesta, la comunicación y el acceso a redes sociales se mantuvieron en primeros lugares seguido de actividades de consumo cultural como entretenimiento y contenidos audiovisuales, seguidos de cerca por la búsqueda de información y apoyo a la educación.
Información amplia sobre los resultados de la ENDUTIH puede consultarse en el comunicado publicado por el INEGI o en la sección misma de la encuesta, explorando los microdatos en el portal correspondiente.
Participación en la primera sesión del conversatorio IA desde las Ciencias Sociales organizado por la Facultad de Ciencias Políticas y Sociales de la UNAM (25 de abril de 2023)
¿Cómo podemos garantizar que los datos utilizados para entrenar los sistemas de IA sean representativos e imparciales? En tal sentido: ¿En qué medida la IA permea la actual polarización política/social? ¿Ahora predominarán las Fake News?
Se me han planteado dos preguntas que revisten implicaciones muy distintas, así que trataré de abordar cada una en la medida de lo que he aprendido de y junto a estas herramientas y lo que, a partir de esas experiencias, creo que puedo decir.
Sobre la primera pregunta, es importante referir a lo que me parece que podríamos llamar sesgos de diseño y que están presentes en los modelos generativos de IA tanto como lo han estado en otras herramientas en la historia reciente de las tecnologías digitales de comunicación interactiva (o lo que otros han llamado TICs). Los sesgos de diseño en la investigación conducen a resultados erróneos y en el caso de herramientas de este tipo, a comportamientos que pueden ser calificados como discriminatorios: sectores de usuarios cada vez menos representados, cuyos intereses no son ponderados por los algoritmos o prácticas discursivas que terminan invisibilizadas por aquello que las tecnologías premian y que no siempre es lo que las sociedades que las usan más requieren.
En todo caso, el hecho de que estos sesgos nos hayan acompañado en las últimas décadas de desarrollo digital no implica que sean irresolubles y haya que resignarse a ellos. Safiya Umoja Noble (2018) ha denunciado el sexismo y racismo algorítmico y visibilizar estos fenómenos ha permitido intervenirlos. Eso me hace creer que los sesgos que empezamos a identificar en las IA pueden, con tiempo y el trabajo de análisis necesario, corregirse.
Pero se me pregunta sobre dos aspectos: la representatividad y la imparcialidad. Con respecto a lo primero, tenemos que meditar cómo discutiremos sobre representatividad (¿en términos estadísticos o cualitativos?) ante una máquina que puede ingerir cantidades difíciles de imaginar de datos.
Tuve que preguntar al propio Chat-GPT a cuánto ascendia la información usada para su entrenamiento: el repositorio Common Crawl consiste en aproximadamente 300 terabytes. ¿Es esto mucho, poco, suficiente?
Se vuelve difícil imaginar cómo la máquina de IA podría ser capaz de reproducir una visión del mundo que no sea la dominante cuando gran parte de su desarrollo se está dando desde los propios polos dominantes
Pensemos en una persona que toma una fotografía cada segundo. El archivo de cada imagen pesa 3 megabytes, a esa persona le tomaría 10 mil años acumular 300 Terabytes.
Para llenar esa cantidad, Chat GPT usó distintos tipos de fuentes de datos: redes sociales como Twitter y Reddit, sitios de noticias como BBC y New York Times así como libros y revistas, pero también blogs y foros en los que cualquiera de nosotros pudo haber participado… y por supuesto, informes provenientes de gobiernos (Estados Unidos, Canadá, Francia, Inglaterra, Australia, China… etcétera).
Y modelos de este tipo siguen en entrenamiento y es muy probable que, en algún momento, este proceso de datificación de la realidad llegue a un nivel en el que no haya “prácticamente” (e insisto en el énfasis) nada que los modelos de IA no sepan. Por lo que todo dato imaginable estará “representado” (y añado de nuevo el énfasis) en los modelos generativos.
Sin embargo, como el modelo ingiere todo, cabe esperar que aquellos polos de producción simbólica dominantes introduzcan en los modelos el sesgo suficiente para que sean esas representaciones y valoraciones (normativas, estéticas, políticas) las que reciban mayor atención de los modelos, sean por tanto más reproducidas y, eventualmente, consumidas.
Lo que sugiero con lo anterior es que se vuelve difícil imaginar cómo la máquina de IA podría ser capaz de reproducir una visión del mundo que no sea la dominante cuando gran parte de su desarrollo se está dando desde los propios polos dominantes. Las ideas de la clase dominante son las ideas dominantes en cada época sugerían un tal Marx y un tal Engel hace mucho tiempo, y a mi parecer, estas nuevas herramientas no se alejan mucho de aquel postulado.
Entonces, el hecho de que todo dato se encuentre representado en los modelos generativos no nos garantiza que todos estemos representados en las respuestas que nos ofrecen. Por el contrario, estamos en un escenario en el que hay una alta probabilidad de que ocurra lo contrario y que sean las ideas dominantes las que, de nuevo, encuentren un nicho (reluciente y potente) de reproducción. ¿Es esto inevitable? Yo creo que no.
Pensemos en las siguientes imágenes.
Imágenes generadas con Dall-e en Bing para el prompt: una mujer saliendo de la pantalla de un ordenador en versión arte digital.
Cuando al modelo se le da la instrucción, ofrece rostros y composiciones físicas de mujeres blancas. Por ello, se hace necesario añadir en la proposición (como se hizo para la imagen de la izquierda) que la mujer que sale de la pantalla es de rasgos afroamericanos, pues de otro modo, Dall-e seguirá produciendo una mujer blanca una y otra vez.
El modelo, como se puede ver, sabe cómo representar a una mujer afroamericana, pero no lo hace por sí mismo, hay que indicárselo. ¿Por qué? ¿Por qué las representaciones resultados del mismo prompt no varían entre cuerpos negros, morenos, asiáticos, etc.? ¿Por qué deben ser siempre cuerpos y pieles blancas? Esto no quiere decir (como puede ser fácil afirmar) que Dall-E es racista, pero sí nos da elementos para señalar que su diseño tiene un sesgo que reproduce el racismo estructural de la sociedad que construyó este modelo generativo.
De ello cabe decir que, para que el modelo mejore en este sentido (como deberá hacerlo en otros), se hace necesario identificar estos sesgos de diseño. Y la manera de identificar los problemas de la máquina es aprendiendo a usarla, conociendo cómo se alimenta y poniéndola a prueba.
IA y polarización, ¿cómo plantear la relación entre sendos fenómenos?
Las siguientes preguntas que se me plantean se podrían englobar en el problema tanto social como de conocimiento que estriba en los fenómenos de desinformación y polarización política.
Para esto me gustaría mostrar solo unos cuantos datos. Decidí hacer una descarga de publicaciones de Twitter que abarcó desde el 1 de diciembre de 2022 y concluyó el 31 de marzo pasado. Busqué tweets en español que usaran el término “chat gpt” en el texto. El resultado fueron casi 220 mil publicaciones pero, como se ve en la gráfica que se muestra a continuación, lo que vemos es una tendencia que se ha mantenido durante los últimos meses y que muestra el interés creciente en una de las muchas herramientas de IA disponibles al gran público.
Fuente: Elaboración propia con datos extraídos de Twitter. Consultable en el enlace.
Cuando a principios de febrero, Chat GPT alcanzó sus primeros 100 millones de usuarios, entramos en un punto de no retorno no para la tecnología sino para nosotros como usuarios en términos de adopción de la herramienta. En este sentido, me parece que la preocupación sobre los fenómenos de desinformación, si bien justificada entre algunos sectores de la opinión pública y la academia debido a no pocos ejemplos de manipulación de plataformas en la historia reciente, aunque está presente entre los usuarios de los modelos generativos, no es la principal.
En la parte inferior izquierda del tablero están representados poco más de 3,600 mensajes, una fracción muy pequeña de los casi 220 mil producidos en español en un periodo de cuatro meses y si bien algunos refieren a temas como desinformación, noticias falsas y posibles usos maliciosos de modelos como Chat GPT, la mayoría en realidad señalan “errores” de la máquina: la forma en que ”alucina” al momento de tratar de dar respuesta a una pregunta para la que no tiene información, la producción de autores, títulos y afirmaciones inexistentes en la literatura académica, la incapacidad (temporal, habría que decir) del modelo para ser infalible.
Los usuarios están poniendo a prueba la fiabilidad de la máquina y eso es no solo pertinente sino necesario. ¿Puede ser usado Chat GPT para producir noticias falsas? Por supuesto: es una herramienta sumamente potente que está disponible de forma relativamente accesible (su versión de pago está a la par de algunos servicios de video en streaming). ¿Puede esto exacervar los procesos de polarización que ya vemos en algunos países latinoamericanos? No cabe duda. Pero esto está más relacionado con los propios procesos políticos que en determinadas regiones del mundo se están viviendo que con las características propias de la máquina.
Es decir: sin desestimar los perjuicios que el uso nocivo de modelos generativos de inteligencia artificial pueden producir en determinados contextos sociales, el primer lugar de intervención para evitar estos daños a la salud de las democracias contemporáneas está en los propios contextos de acogida de la tecnología.
El uso de este tipo de tecnologías tiene el potencial de exacerbar las condiciones que se presentan en contextos de polarización pero, como ciudadanía usuaria de este tipo de tecnologías, debemos dirigir nuestros reclamos hacia las fuentes de la polarización y a los actores que se han beneficiado de los fenómenos de desinformación.
Quisiera sostener este argumento a partir de lo que hemos visto que ocurre con otras herramientas como las plataformas de redes sociodigitales: el estudio de los procesos de plataformización ha dado cuenta de cómo cierto tipo de lógicas empresariales, en ocasiones de cariz bastante perverso, inciden en otros espacios sociales como lo son gobiernos y vida cotidiana. Ejemplos hay varios: la negligencia de Facebook en el uso y abuso de nuestros datos ha tenido consecuencias en procesos democráticos de diversos países (Cambridge Analytica), ciertos mercados tradicionales han sido invadidos mediante agresivas e incluso violentas estrategias de cabildeo ante gobiernos en paralelo a prácticas de intrusión de datos y espionaje corporativo (Uber), y las plataformas más populares de red social han sido incapaces para dotar a sus usuarios de herramientas efectivas para combatir la propagación de información falsa y maliciosa, además de para identificar y prevenir distintas formas de violencia digital.
Pero todos estos ejemplos han ocurrido con la connivencia de los poderes establecidos. Los distintos actores políticos han hecho poco y mal trabajo tratando de prevenir el uso malicioso de las plataformas. Aunado a ello, los intentos de regulación muchas veces se dirigen hacia los usuarios, lo que se ha advertido puede atraer un contexto menos democrático en términos de libre expresión. Y es en este tipo de contexto que estamos empezan a adoptar y apropiar los modelos generativos de IA.
Imágenes producidas mediante modelos generativos
Los modelos generativos pueden y seguramente serán usados de forma maliciosa sistemáticamente y esto exige esfuerzos en varios sentidos. Por un lado, se nos plantea un nuevo problema para los procesos de alfabetización digital, como profesionales de la comunicación o académicos debemos proveer a nuestras comunidades de recursos y herramientas que les permitan mantenerse adecuadamente informados y suficientemente alertas para poder identificar flujos de desinformación. Por otra parte, este mismo contexto exige de los actores sociales involucrados una participación más decidida en la producción de contenidos informativos confiables para los grandes públicos. Los medios masivos de comunicación han fallado en ese sentido durante un largo tiempo. No solo han desestimado a sus audiencias sino que se han adaptado poco y mal al nuevo contexto comunicacional… de las últimas dos décadas se podría decir.
Es decir, el uso de este tipo de tecnologías tiene el potencial de exacerbar las condiciones que se presentan en contextos que han sido objeto de procesos de polarización, como lo es México. Pero por alarmante que sea esta posibilidad, como ciudadanía usuaria de este tipo de tecnologías, debemos dirigir nuestros reclamos hacia las fuentes de la polarización y a los actores que se han beneficiado de los fenómenos de desinformación.
Por optimista que pueda parecer, no creo que nos vayan a inundar las noticias falsas. Eso, si ha de ocurrir, falta por verse. Pero si eso ocurre, no será tanto a causa de las cualidades de estas herramientas tecnológicas como por el espírituo con que pueden ser usadas por actores sociales y políticos que sí podemos identificar.
Por último y para poder continuar el diálogo con ustedes, creo que es pertinente decir que en algunos sectores de la academia y los medios, hay una alarma e incluso animadversión hacia los modelos generativos como si estos fueran a acabar con la sociedad como la conocemos. En este sentido, me parece que algunas valoraciones son más que nada normativas antes que basadas en evidencia. Es decir, algunos analistas están poniendo el carro delante de los caballos al tratar de predecir qué ha de ocurrir con las IA.
Estamos en un proceso en el que solo podemos ver una forma temporal de este tipo de herramientas. Con toda seguridad, los modelos generativos cambiarán a formas que aún no nos imaginamos y con probabilidad lo harán muy rápidamente. Piénsese en las redes sociodigitales, en el páramo de actualizaciones desarticuladas que eran a finales de la primera década de este siglo y cómo a fuerza de apropiación colectiva y mutuas contaminaciones entre distintas tecnologías adquirieron la forma con que las conocemos hoy. Las IA (que han estado con nosotros más tiempo del que creemos a primera vista) están empezando su aceleración y en términos de construcción social de la tecnología, estamos tratando de revelar sus controversias como parte del proceso de adopación. La forma en que resolvamos estas inquietudes nos llevarán por un camino u otro. Nuestro deber, desde las Ciencias Sociales, es no perder detalle de este proceso y, creo, tratar de entenderlo para después explicarlo. A la sociedad y a nosotros mismos.
Referencias
Noble, S. U. (2018). Algorithms of oppression: How search engines reinforce racism. New York University Press.