Si la IA es el medio, la ciencia debe ser el mensaje
Diseñar investigación sobre IA, reto y oportunidad en la comunicación
Inicia el ciclo de mesas de discusión “Debates actuales en estudios de comunicación, cultura y sociedad” en el IIS-UNAM
Académicos de UAM y CIIDET participan en la sesión “Aproximaciones metodológicas contemporáneas a los estudios de comunicación”
Escrito por Antony Flores Mérida
en
En tiempos de modelos generativos de inteligencia artificial, recordar la máxima de Marshal McLuhan cuando postulaba que “el medio es el mensaje” obliga a la reflexión crítica ante las posibilidades que las tecnologías emergentes nos plantean: “si la inteligencia artificial es el medio, ¿cuál es el mensaje” expuso César Rodríguez Cano, profesor investigador de la UAM-Cuajimalpa al participar el el ciclo “Debates actuales en estudios de comunicación, cultura y sociedad” en el Instituto de Investigaciones Sociales (IIS) de la UNAM. El investigador de la Universidad Autónoma Metropolitana participó junto a la profesora investigadora del Tecnológico Nacional de México, Dra. Ileana Cruz-Sánchez, en la mesa titulada “Aproximaciones metodológicas contemporáneas a los estudios de comunicación: tradición, convención e innovación” en la que expusieron las discusiones, tensiones y hallazgos de sus agendas de investigación y formación en el terreno metodológico. Durante el cierre de la discusión y cuestionados sobre los retos y oportunidades de aprender e investigar en el contexto de adopción de las tecnologías de inteligencia artificial generativa, Rodríguez Cano planteó que “si la inteligencia artificial es el medio, no dejemos que también sea el mensaje, (…) la ciencia tiene que ser el mensaje” por lo que instó a que desde los espacios de producción de conocimiento se produzcan dinámicas para ir planteando los límites y cuestionamientos que se deben plantear ante estos desarrollos tecnológicos y sus posibilidades para la investigación en distintos campos, entre los que se encuentran las Ciencias Sociales y las Humanidades Ileana Cruz-Sánchez del campus CIIDET del Tecnológico Nacional de México señaló por su parte que es importante apropiar y transmitir el conocimiento sobre los modelos generativos “con inmensa humildad (…), aceptar que no lo sabes y vamos a aprender juntos, estudiantes y docentes” en un campo que plantea diversos retos por lo desconocido que aún es y por su propia condición de fenómeno en desarrollo. Ante los fenómenos sociales y de comunicación emergentes en el actual momento, plantearon la necesidad de utilizar y proveer de densidad teórica a las categorías de análisis que usamos para aproximarnos a las prácticas mediadas por las tecnologías; “es importante que esta densificación provenga no de un rompimiento teórico con lo que ya se sabía, caeríamos en un error al pensar que los ‘nuevos’ fenómenos no pueden ser entendidos con categorías ‘viejas’” planteó Rodríguez Cano. En ese sentido, Ileana Cruz-Sánchez consideró que puede ser “mucho más interesante ampliar los paraguas teóricos” existentes, poniendo como ejemplo el caso de la etnografía que, como aproximación metodológica y forma de investigación se desarrolla en espacios sociodigitales. César Rodríguez Cano, autor del libro Hipermétodos, expuso sus reflexiones en torno a los retos metodológicos que plantean las irrupciones tecnológicas, especialmente los modelos generativos de IA, en la investigación de la comunicación. Por su parte, Ileana Cruz-Sánchez, quien ha realizado investigación en temas como videojuegos, habilidades STEM entre niñas y violencia digital, compartió algunos de sus hallazgos en estos rubros durante su participación en la sesión del ciclo de debates. La primera sesión forma parte de un conjunto de cinco mesas organizadas por Antony Flores Mérida, becario posdoctoral en el Instituto de Investigaciones Sociales de la Universidad Nacional Autónoma de México. Otros temas a desarrollarse durante el ciclo serán la relación entre medios y poder en contextos de autoritarismo, los fenómenos de desinformación y la investigación en torno a periodismo y libertad de expresión contemporáneas.
Hannah Ajakaiye, reconocida periodista y directora de FactsMatterNG, combate la desinformación en las elecciones nigerianas mediante la verificación de hechos y el trabajo colaborativo de organizaciones de fact-checking. Comsocyc En la preparación para las elecciones...
Esta edición del congreso se realizará en Bogotá, Colombia, del 12 al 15 de junio de 2024 Invita a reflexionar sobre el presente y futuro de las Américas. Propuestas de participación se recibirán hasta el 15 de septiembre de 2023 Comsocyc Bogotá será el epicentro del...
El Consejo Mexicano de Ciencias Sociales y el Instituto de Investigaciones Sociales de la UNAM anunciaron el IX Congreso Nacional de Ciencias Sociales: «Las ciencias sociales y los retos para la democracia mexicana». El evento se llevará a cabo en el Instituto de Investigaciones Sociales de la UNAM, del 8 al 12 de abril de 2024.
El presente texto fue elaborado a partir de distintos testimonios, por lo que su autoría, si bien se sugiere anónima, en realidad es resultado de múltiples voces que se coordinaron y articularon desde los primeros momentos de la tragedia del 19 de septiembre de 2017. Su esfuerzo y trabajo ocurrió a distintos ritmos, desde variadas plataformas, espacios y tiempos, no solo a través de lo sociodigital sino, sobre todo, en el desastre: los edificio derrumbados, los albergues saturados, los acopios desbordados, el país removido. En la búsqueda de que su dedicación no sea olvidada, recuperamos estos fragmentos y los presentamos como una sola voz que sintetiza la respuesta ciudadana ante la tragedia.
A veces recuerdo esos días y no entiendo cómo pasaron tantas cosas en tan poco tiempo. Por ejemplo, el día del terremoto yo estaba en Polanco porque tenía que hacer los trámites para una Visa, estaba por irme del país, era una oportunidad muy importante para mí, estaba nerviosa y emocionada. Regresaba de mi trámite comiendo un helado y me quedé esperando un poco afuera del Metro Auditorio. No quería entrar porque el helado se me iba a derretir. Justo en ese momento empezó a temblar.
Me quedé ahí, en pleno Reforma, se habían perdido las comunicaciones y no tenía cómo moverme así que me puse a caminar. Se me ocurrió contactarme con uno de mis amigos que vive por la Roma. Me contestó muy agitado así que le pregunté si estaba bien. Estaba corriendo, tenía que ir por su hijo a la escuela, ¿te imaginas? Él trabaja en cuestiones de informática y dejó tirado todo para ir corriendo a la escuela de su hijo. Cuando le marqué él estaba pasando frente a los derrumbes. “Huele mucho a gas” me dijo, “la gente está corriendo y hay edificios caídos”. De verdad que no le podía creer. Me dijo que luego me marcaba. Me quedé pensando cómo me sentiría si tuviera un hijo o hija en la escuela y estuviera como él, corriendo entre los edificios derribados por el sismo.
En eso me llegó la noticia de que el edificio en el que yo vivía, en la Narvarte, se había caído. Lo primero que se me ocurrió fue preguntar en Twitter si alguien estaba cerca y podía verificar el derrumbe. Estaba preocupada, tenía una “roomie” y ella seguro estaba en el edificio, pero no podía comunicarme con ella. Un ciclista que iba pasando, no recuerdo quién era, pero tomó una foto y me respondió que todo estaba bien.
Aunque hacer llamadas estaba imposible, el internet del teléfono no se me fue así que empecé a reportarme con la gente que conozco por WhatsApp, preguntando cómo estaban. Tenía algunos contactos de la universidad, de cuando andábamos en el movimiento, y empezaron a reportarse. Después de varios años de activismo ya sabíamos que cuando pasaba algo teníamos que reportarnos y, si alguien necesitaba ayuda, podíamos organizarnos para ir corriendo a ver cómo apoyarlo. Pero todos estábamos bien. Luego los colegas de trabajo, algunos ya andaban pensando cómo acopiar víveres para los albergues porque estábamos viendo en redes que esto era gigantesco.
Justamente a alguien en esos grupos se le ocurrió hacer un mapa, en Google, y nos mandó el enlace. La idea era que si andábamos en la calle y veíamos algún daño, lo pusiéramos en el mapa. Yo, la verdad, sé muy poco de tecnología, pero algunas personas que conozco sí saben cómo moverse en ese ambiente y les empecé a mandar fotos de donde andaba.
Pero no era suficiente y en cada grupo de WhatsApp todos sentían lo mismo, lo estaban diciendo. Para la noche, apenas empezábamos a imaginar el tamaño del desastre. ¿Qué podíamos hacer? No lo sabíamos.
Dos amigos que son pareja empezaron a mandar mensajes, yo la conocía a ella porque es ambientalista y a él porque anda metido en activismo político. Habíamos coincidido en foros, cosas por el estilo. Resulta que conocían también a uno de mis amigos de sistemas, programador. Y todos preguntaban lo mismo, ¿qué podíamos hacer? Yo pensaba que las redes iban a ayudar pero de pronto todo era ruido, un caos, en las calles y en las redes.
Fue justo el esposo de esta amiga ambientalista quien dijo que teníamos que juntarnos en algún lugar. Alguien propuso su casa, pero era en Coyoacán y lo primero que pensaron algunos es que había que estar lo más cerca posible de las zonas afectadas. De pronto alguien mencionó Horizontal, lo estaban ofreciendo para que nos reuniéramos a la mañana siguiente.
Cuando llegué ya había varias personas ahí. Me sorprendió que mi amigo, el que mandó el mapa de Google ya estaba ahí, también la pareja de esposos activistas. Yo le mandé un mensaje a mi amigo programador, me dijo que en su trabajo le habían dado el día por el sismo y que me alcanzaba en un rato. ¿Puedo invitar a más gente? Me preguntó, cuando le hice la misma pregunta a los que ya habían llegado dijeron que sí, que entre más manos, mejor. “Tráete a tu gente” le dije.
—¿Qué vamos a hacer? —me preguntó entonces.
—No sé, no sabemos, pero algo se nos va a ocurrir.
—Le diré a mi equipo que me alcance allá, sólo mándame la ubicación— y nos despedimos.
Empezamos a platicar, lluvia de ideas. Mi amigo el del mapa dijo que él estaba haciendo eso pero que tenía problemas, la gente no sabía cómo utilizarlo y de pronto también era un caos.
—Tenemos que organizar la información, sólo así vamos a poder ayudar, sólo así la gente va a poder ayudar —dijo uno de los asistentes.
Saqué una libreta, nos juntamos en una mesa y empezamos a pensar cómo armar todo. Cuando llegó mi amigo el programador y nos vio en los teléfonos y las computadoras y anotando todo en libretas no lo podía creer. Volvimos a armar una reunión, nos dijo que si queríamos que esto funcionara teníamos que producir datos de una manera en que la gente pudiera consultarlos, pero también, alimentarlos, ayudar. ¿Sabes qué decidimos? Armar una base con la información. Empezamos a llamar a amigos que andan en organizaciones, en gobierno, en la calle, para que nos ayudaran.
No era ni medio día y ya éramos más de veinte poniéndonos las pilas. Y cada uno de nosotros empezó a llamar a más gente. De pronto, nos dimos cuenta que necesitábamos también tener un nombre para empezar a difundir en redes, para que la gente nos encontrara.
—¿Cómo nos vamos a llamar? —dijo alguien mientras hacíamos un círculo rápido en medio de la sala.
—¿Qué les parece hashtag Verificado 19 S? —cruzamos algunas miradas entre nosotros, sonaba bien— ¿Todos a favor? ¿Alguien en contra? –no tuvimos que decir más.
—Es un hecho, nos llamaremos #Verificado19s.
Para la noche del día después del sismo ya habíamos llenado una bodega y un camión con víveres, teníamos un nombre, estábamos haciendo una base de datos y levantando un sitio web. Yo no sé casi nada de tecnología pero busqué gente, ofrecí ayuda, di mi opinión. Algunos dicen que salvamos vidas. Que la llamada que hiciste, el camión de víveres que mandaste a tal o cual lugar, sirvió para salvar vidas. Yo no lo sé. Sigo sin entender cómo pasaron tantas cosas en tan poco tiempo.
Verificado19s fue un movimiento ciudadano que, mediante el uso de redes sociodigitales, buscó reducir la incertidumbre en el momento de la tragedia. Imagen generada mediante Dall-E (Bing)
El texto aportado líneas arriba forma parte de la tesis de grado Redes de Movimiento: #Verificado19s, formación y transformación de actores colectivos a través de campañas de acción digitalmente mediada (Flores Mérida, 2021)
Partiendo de la pregunta ¿Qué se discute en Twitter sobre la revocación de mandato? se descargaron casi 10 mil tuits con el hashtag #revocaciondemandato (sic) de la plataforma de red social Twitter. Los datos resultantes se procesaron para mapear interacciones y detectar comunidades de discusión.
Este ejercicio busca poner a prueba la idea de que el peso de la crítica tiene cierto efecto en el reconocimiento que un filme logra. Se verá cómo la calificación que las audiencias ofrecen a una película está asociada positivamente con el número de premios que ésta recibe.
A partir de dos extracciones de datos de la red social Twitter, buscamos evaluar dos cosas: ¿hacia quién se dirigen las interacciones en el marco de la contingencia por COVID-19? y por otra parte, ¿entre quiénes se entrelaza la conversación digital?
Tanto en plataformas de redes sociales como en las tendencia de Google, de los aspirantes de MORENA, Sheinbaum y Ebrard son los que destacan
A una semana de actividad política de los aspirantes a la candidatura de la 4T, las tendencias sociodigitales dan ventaja a Claudia Sheinbaum en una carrera cerrada a solo dos competidores
Antony Flores Mérida
Las interacciones en espacios sociodigitales dan pistas que nos ayudan a interpretar la forma en que se desenvuelven determinados acontecimientos (culturales, sociales, políticos…). En este sitio se han realizado exploraciones a la discusión digital en temas como la revocación de mandato o la emergencia por COVID-19 en Twitter. Uno de los temas del momento es el proceso de selección de las candidaturas presidenciales rumbo a la elección de 2024 y en los distintos espacios sociodigitales, la selección de la candidatura de MORENA (y la 4T) ocupa los primeros lugares en la conversación.
Una pequeña muestra de videos de la red social que utilizan la palabra “corcholatas” permitió obtener datos de 440 publicaciones a las cuales se le extrajeron las etiquetas (hashtags) utilizados. La exploración se puede apreciar en la nube de palabras que se ofrece a continuación.
Los datos de esa pequeña muestra dan cuenta de cómo las etiquetas referentes a la ex Jefa de Gobierno de la ciudad de México, Claudia Sheinbaum y las del ex titular de la SRE, Marcelo Ebrard, son las más presentes en los 440 videos obtenidos en la búsqueda. No debemos pasar por alto que distintas etiquetas referentes al presidente se encuentran con una gran frecuencia en esta plataforma (AMLO, 4T, Amlovers, CorcholatasDeAMLO, LopezObrador, entre otras).
Nube de palabras elaborada a partir de las etiquetas presentes en 440 videos de la red social Tik Tok que mencionan la palabra «corcholadas».
Entre los aspirantes, el ex titular de SEGOB, Adán Augusto López, aparece en tercer lugar en menciones (aunque por cada tres menciones de Sheinbaum o Ebrard hay una de Adán Augusto). Los aspirantes Gerardo Fernández Noroña y Ricardo Monreal tienen casi el mismo nivel de menciones mientras que el aspirante del Partido Verde, Manuel Velasco, solo aparece en tres menciones en esta muestra de datos.
¿Esta tendencia está presente en otros espacios de conversación? ¿Qué nos dicen estos patrones de la contienda interna en MORENA para definir su candidatura presidencial? Para tratar de ensayar respuestas a estas cuestiones se presentan, de forma exploratoria, algunos datos de las plataformas Twitter y Google Trends.
La relación entre procesos electorales y tendencias sociodigitales
El uso de técnicas de big data como predictor de comportamientos políticos ha estado presente desde hace algunos años en el análisis de la ciencia política. Un trabajo de Prado-Román y otros (2021) cita, entre otras investigaciones, la de Christine Ma-Kellams et al. (2017) sobre el uso de Google Trends como predictor de resultados electorales. Prado-Román y sus compañeros asumen que el número de términos de búsqueda utilizados por los usuarios de plataformas sociodigitales pueden dar cuenta de la forma actual y futura de pensar y actuar de sectores importantes de la población (2021, p. 3).
Los autores del estudio citado plantean, sin embargo, una caución, y es que este tipo de «predictores» sólo funcionan en procesos democráticos y en territorios donde no hay restricciones para el uso de tecnologías digitales de comunicación interactiva. Aunque los autores ponen a prueba sus hipótesis en los casos de elecciones de Estados Unidos y Canadá, este bien podría aplicarse al contexto mexicano.
Sin embargo, no nos encontramos ante una elección presidencial sino ante el proceso interno de un grupo de partidos para elegir a la persona que, eventualmente, será su candidato/a presidencial. Por ello, más que un predictor, para esta exploración los datos pueden bien dar cuenta del ‘estado de la conversación sociodigital’ pues, a final de cuentas (y pese a que el proceso de MORENA contempla una encuesta), no estamos ante un proceso electivo convencional.
La conversación en Twitter
Durante la primera semana de actividad de las personas que buscan encabezar los “comités de defensa de la 4T” (término usado por MORENA y sus partidos aliados para quien, presumiblemente, será la persona que ostentará la candidatura presidencial), se recogieron 1.1 millones de publicaciones que mencionan los nombres o usuarios de Twitter de los cinco principales contendientes. Aunque la exploración a profundidad no se presenta en esta ocasión, sí una breve visualización de 75 mil publicaciones únicas emitidas durante los días sábado y domingo al concluir su primera semana de actividades.
Al igual que ocurre en la pequeña muestra de datos de Tik Tok, en Twitter el patrón emerge de nuevo: la aspirante Claudia Sheinbaum es la más mencionada en esta muestra de datos (casi 35 mil ocasiones, es decir, prácticamente la mitad de los datos presentes) mientras que Marcelo Ebrard tiene un 50% menos menciones que la ex Jefa de Gobierno (17.2 mil). En esta red social, Adán Augusto está más cerca del ex canciller de lo que ocurrió en Tik Tok con unas 16 mil menciones. El resto de aspirantes se encuentra, sin embargo, más lejos: Fernández Noroña logra unas 3 mil 500 y Ricardo Monreal unas 3 mil 200.
Nube de palabras elaborada a partir de una muestra de 75 mil publicaciones en Twitter que mencionan a alguno de los aspirantes a la candidatura presidencial de MORENA.
En esta muestra de datos (y a expensas de explorar la serie que abarca toda la semana), Claudia Sheinbaum es más mencionada en la plataforma Twitter superando por mucho a cualquiera de sus compañeros contendientes. Ebrard y Adán Augusto tienen una cantidad muy similar de menciones mientras que Noroña y Monreal, con cantidades muy parecidas, están muy lejos en la carrera de las menciones en Twitter.
Google Trends: una carrera presidencial entre dos aspirantes
La carrera por la candidatura de la 4T para el proceso de 2024 está, como se puede ver, muy marcada en distintas plataformas. En Google parece ocurrir algo muy similar.
Los servicios de Alphabet permiten a las personas usuarias buscar información, noticias, imágenes, videos… en toda la web. Google es uno de los servicios más usados por los mexicanos –de hecho, nuestro país es uno de los 10 que más usan los servicios de la empresa– y por ello, las tendencias de búsqueda en este servicio son un punto a considerar.
Para este ejercicio realizamos, en un navegador (Safari) y con opciones de anonimización (sin registro en cuenta de Google y con navegación privada) una consulta a Google Trends en la que colocamos los nombres de los cinco aspirantes principales a la candidatura de MORENA y sus partidos aliados.
Al colocar los nombres, en lugar de referirlos como “Tema” se eligió la opción de “Término de búsqueda” para todos los casos, para tratar de simular la conducta natural de un usuario promedio. La exploración contempla las mediciones para los últimos 30 días (con corte al 29 de junio de 2023) y se ha elegido la “Búsqueda web” como parámetro (en lugar de Noticias o cualquier otra opción).
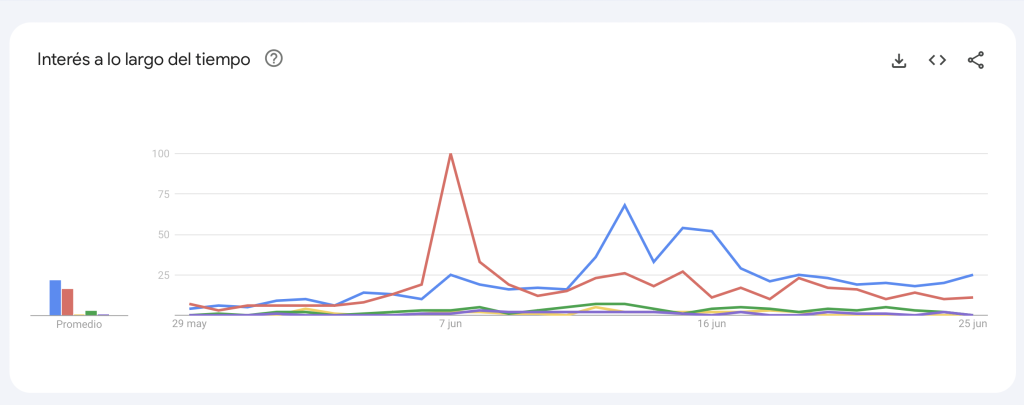
La primera gráfica muestra el “Interés a lo largo del tiempo” para el periodo seleccionado. El color azul representa a Claudia Sheinbaum, el rojo a Marcelo Ebrard, el amarillo a Adán Augusto López, el verde a Ricardo Monreal y el violeta a Fernández Noroña.
Gráfico de interés a lo largo del tiempo. Elaborado mediante Google Trends.
Al igual que ocurre en plataformas de red social, Sheinbaum parece contar con la mayor atención por parte de los usuarios y la comparte con Marcelo Ebrard.Los momentos de mayor volumen de búsquedas para cada uno coinciden (como cabe esperar) con eventos altamente mediatizados. La fecha con mayor número de búsquedas sobre la ex Jefa de Gobierno es el 13 de junio (en una tendencia que inicia varios días antes) un día después de que anunciara que pediría licencia a su cargo el 16 de junio días en los que ocupa los volúmenes más altos de búsquedas en Google. De hecho, las palabras relacionadas a su renuncia son las que ocupan los primeros lugares.
Por su parte, Marcelo Ebrard tuvo el volumen más alto de búsquedas el 7 de junio después de que anunciara que sería el primero de los aspirantes a la candidatura de la 4T en dejar su cargo y aunque mantuvo la atención de los usuarios por un par de días, el volumen de búsquedas relacionadas al ex canciller ha ido en descenso y se mantiene por debajo de las búsquedas sobre Sheinbaum Pardo. Al final del periodo observado, Claudia Sheinbaum mantiene un nivel de interés de 25 mientras que Ebrard se coloca en 11 (valores relativos a 100, el momento máximo para todo el periodo).
El resto de los aspirantes han tenido volúmenes de búsqueda muy por debajo de estos dos punteros y solo Ricardo Monreal ha llegado a niveles de atención (un máximo de 7 sobre 100) en algunos de los días previos al inicio de las giras de los aspirantes, el 19 de junio.
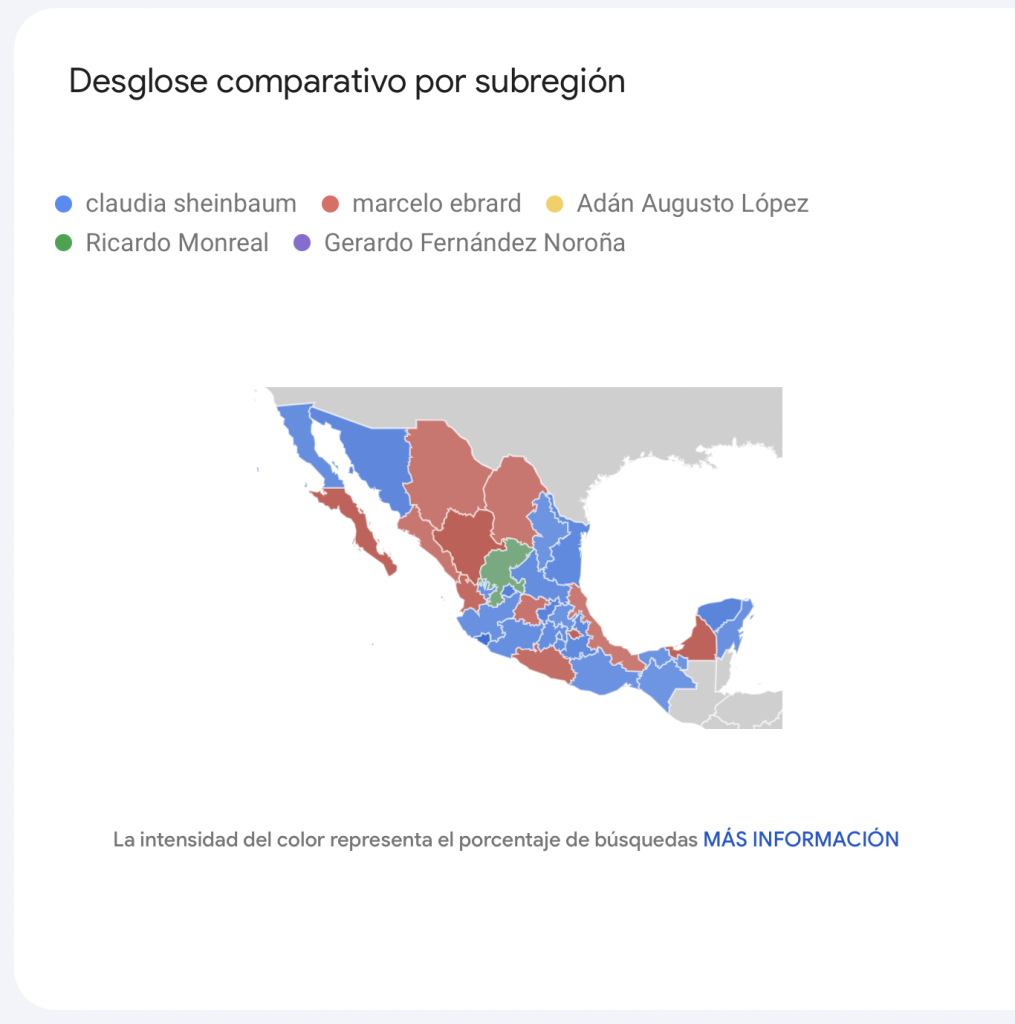
La forma en que la atención de los usuarios de Google se distribuye en el territorio también puede ser llamativa. El mapa muestra el color correspondiente a cada aspirante que se ubicó con el primer lugar en volumen de búsquedas para el periodo observado.
Comparación de las búsquedas en Google en distintas regiones del país. Elaborado con Google Trends.
Sheinbaum destaca en estados como Colima, Aguascalientes, Querétaro, Yucatán y Sonora con los niveles de atención de los buscadores más altos; Ebrard por su parte aparece con mayor presencia en búsquedas desde Durango, Tlaxcala, Campeche, Baja California Sur y Nayarit. Para la primera, la atención ha ido en aumento en Sonora pero también en Sinaloa, mientras que en el caso de Ebrard, la atención ha empezado a subir en estados del sur como Oaxaca y Guerrero, así como en algunas zonas del centro como el Estado de México.
En cuanto a Adán Augusto López, las búsquedas sobre el ex gobernador de Tabasco solo han tenido cierta densidad (aunque sin llegar a primeros lugares) en zonas del sur como Chiapas, Guerrero y Yucatán. Ricardo Monreal obtiene el primer lugar en interés en Zacatecas (de donde es originario y que gobernó de 1998 a 2004) mientras que Fernández Noroña, que no destaca en ningún estado, mantiene cierto interés en Hidalgo.
De las tendencias a los eventos políticos
¿Son las conductas de personas usuarias de las plataformas un indicador de preferencias electorales? ¿Son estas tendencias resultado o causa de la forma particular en que ciertos mensajes políticos se mediatizan? Si se han de seguir los supuestos de Prado-Román et al. (2021) y otros estudios que afirman la relación que existe entre conductas de búsqueda en línea y resultados electorales, se podría afirmar, por ejemplo, que la atención que Claudia Sheinbaum mantiene en redes como Twitter y Tik Tok así como los datos sobre búsquedas en Google permiten anticipar que esta se colocará en las preferencias de las encuestas que realizará MORENA y será, eventualmente, la candidata a la presidencia del proyecto político de la 4T.
Tan solo en el caso de Google Trends, el volumen promedio de la atención hacia Sheinbaum Pardo es cinco puntos mayor que la que se da a Marcelo Ebrard (22 vs. 17, promedio para todo el periodo). Sin embargo, en algunos periodos la diferencia entre ambos se cierra por lo que son los eventos de las giras (o campañas) de los aspirantes los que habrán de dar forma a estas tendencias.
Lo que parece más claro es que la competencia interna de MORENA se definirá entre estos dos personajes pues el resto (incluido el ex titular de SEGOB, Adán Augusto López) no cuentan con suficiente atención por parte de los usuarios en términos generales y solo logran cierta tracción en algunos estados, aunque siempre la comparten con los dos punteros.
Luego de una semana de activismo electoral, las tendencias pues, parecen definidas hacia dos aspirantes. Aunque aún falta tiempo de giras de los aspirantes (o asambleas, como las define MORENA) hasta finales de agosto y la encuesta no se realizará sino en los días posteriores a esta actividad, si alguna sorpresa depara el proceso interno de la 4T, ésta no debería tardar en presentarse.
REFERENCIAS
Ma-Kellams, Christine & Bishop, Brianna & Zhang, Mei & Villagrana, Brian. (2017). Using “Big Data” Versus Alternative Measures of Aggregate Data to Predict the U.S. 2016 Presidential Election. Psychological Reports. 121. 003329411773631. 10.1177/0033294117736318.
Prado-Román, C., Gómez-Martínez, R., & Orden-Cruz, C. (2021). Google Trends as a Predictor of Presidential Elections: The United States Versus Canada. American Behavioral Scientist, 65(4), 666-680. https://doi.org/10.1177/0002764220975067
Participación en la primera sesión del conversatorio IA desde las Ciencias Sociales organizado por la Facultad de Ciencias Políticas y Sociales de la UNAM (25 de abril de 2023)
¿Cómo podemos garantizar que los datos utilizados para entrenar los sistemas de IA sean representativos e imparciales? En tal sentido: ¿En qué medida la IA permea la actual polarización política/social? ¿Ahora predominarán las Fake News?
Se me han planteado dos preguntas que revisten implicaciones muy distintas, así que trataré de abordar cada una en la medida de lo que he aprendido de y junto a estas herramientas y lo que, a partir de esas experiencias, creo que puedo decir.
Sobre la primera pregunta, es importante referir a lo que me parece que podríamos llamar sesgos de diseño y que están presentes en los modelos generativos de IA tanto como lo han estado en otras herramientas en la historia reciente de las tecnologías digitales de comunicación interactiva (o lo que otros han llamado TICs). Los sesgos de diseño en la investigación conducen a resultados erróneos y en el caso de herramientas de este tipo, a comportamientos que pueden ser calificados como discriminatorios: sectores de usuarios cada vez menos representados, cuyos intereses no son ponderados por los algoritmos o prácticas discursivas que terminan invisibilizadas por aquello que las tecnologías premian y que no siempre es lo que las sociedades que las usan más requieren.
En todo caso, el hecho de que estos sesgos nos hayan acompañado en las últimas décadas de desarrollo digital no implica que sean irresolubles y haya que resignarse a ellos. Safiya Umoja Noble (2018) ha denunciado el sexismo y racismo algorítmico y visibilizar estos fenómenos ha permitido intervenirlos. Eso me hace creer que los sesgos que empezamos a identificar en las IA pueden, con tiempo y el trabajo de análisis necesario, corregirse.
Pero se me pregunta sobre dos aspectos: la representatividad y la imparcialidad. Con respecto a lo primero, tenemos que meditar cómo discutiremos sobre representatividad (¿en términos estadísticos o cualitativos?) ante una máquina que puede ingerir cantidades difíciles de imaginar de datos.
Tuve que preguntar al propio Chat-GPT a cuánto ascendia la información usada para su entrenamiento: el repositorio Common Crawl consiste en aproximadamente 300 terabytes. ¿Es esto mucho, poco, suficiente?
Se vuelve difícil imaginar cómo la máquina de IA podría ser capaz de reproducir una visión del mundo que no sea la dominante cuando gran parte de su desarrollo se está dando desde los propios polos dominantes
Pensemos en una persona que toma una fotografía cada segundo. El archivo de cada imagen pesa 3 megabytes, a esa persona le tomaría 10 mil años acumular 300 Terabytes.
Para llenar esa cantidad, Chat GPT usó distintos tipos de fuentes de datos: redes sociales como Twitter y Reddit, sitios de noticias como BBC y New York Times así como libros y revistas, pero también blogs y foros en los que cualquiera de nosotros pudo haber participado… y por supuesto, informes provenientes de gobiernos (Estados Unidos, Canadá, Francia, Inglaterra, Australia, China… etcétera).
Y modelos de este tipo siguen en entrenamiento y es muy probable que, en algún momento, este proceso de datificación de la realidad llegue a un nivel en el que no haya “prácticamente” (e insisto en el énfasis) nada que los modelos de IA no sepan. Por lo que todo dato imaginable estará “representado” (y añado de nuevo el énfasis) en los modelos generativos.
Sin embargo, como el modelo ingiere todo, cabe esperar que aquellos polos de producción simbólica dominantes introduzcan en los modelos el sesgo suficiente para que sean esas representaciones y valoraciones (normativas, estéticas, políticas) las que reciban mayor atención de los modelos, sean por tanto más reproducidas y, eventualmente, consumidas.
Lo que sugiero con lo anterior es que se vuelve difícil imaginar cómo la máquina de IA podría ser capaz de reproducir una visión del mundo que no sea la dominante cuando gran parte de su desarrollo se está dando desde los propios polos dominantes. Las ideas de la clase dominante son las ideas dominantes en cada época sugerían un tal Marx y un tal Engel hace mucho tiempo, y a mi parecer, estas nuevas herramientas no se alejan mucho de aquel postulado.
Entonces, el hecho de que todo dato se encuentre representado en los modelos generativos no nos garantiza que todos estemos representados en las respuestas que nos ofrecen. Por el contrario, estamos en un escenario en el que hay una alta probabilidad de que ocurra lo contrario y que sean las ideas dominantes las que, de nuevo, encuentren un nicho (reluciente y potente) de reproducción. ¿Es esto inevitable? Yo creo que no.
Pensemos en las siguientes imágenes.
Imágenes generadas con Dall-e en Bing para el prompt: una mujer saliendo de la pantalla de un ordenador en versión arte digital.
Cuando al modelo se le da la instrucción, ofrece rostros y composiciones físicas de mujeres blancas. Por ello, se hace necesario añadir en la proposición (como se hizo para la imagen de la izquierda) que la mujer que sale de la pantalla es de rasgos afroamericanos, pues de otro modo, Dall-e seguirá produciendo una mujer blanca una y otra vez.
El modelo, como se puede ver, sabe cómo representar a una mujer afroamericana, pero no lo hace por sí mismo, hay que indicárselo. ¿Por qué? ¿Por qué las representaciones resultados del mismo prompt no varían entre cuerpos negros, morenos, asiáticos, etc.? ¿Por qué deben ser siempre cuerpos y pieles blancas? Esto no quiere decir (como puede ser fácil afirmar) que Dall-E es racista, pero sí nos da elementos para señalar que su diseño tiene un sesgo que reproduce el racismo estructural de la sociedad que construyó este modelo generativo.
De ello cabe decir que, para que el modelo mejore en este sentido (como deberá hacerlo en otros), se hace necesario identificar estos sesgos de diseño. Y la manera de identificar los problemas de la máquina es aprendiendo a usarla, conociendo cómo se alimenta y poniéndola a prueba.
IA y polarización, ¿cómo plantear la relación entre sendos fenómenos?
Las siguientes preguntas que se me plantean se podrían englobar en el problema tanto social como de conocimiento que estriba en los fenómenos de desinformación y polarización política.
Para esto me gustaría mostrar solo unos cuantos datos. Decidí hacer una descarga de publicaciones de Twitter que abarcó desde el 1 de diciembre de 2022 y concluyó el 31 de marzo pasado. Busqué tweets en español que usaran el término “chat gpt” en el texto. El resultado fueron casi 220 mil publicaciones pero, como se ve en la gráfica que se muestra a continuación, lo que vemos es una tendencia que se ha mantenido durante los últimos meses y que muestra el interés creciente en una de las muchas herramientas de IA disponibles al gran público.
Fuente: Elaboración propia con datos extraídos de Twitter. Consultable en el enlace.
Cuando a principios de febrero, Chat GPT alcanzó sus primeros 100 millones de usuarios, entramos en un punto de no retorno no para la tecnología sino para nosotros como usuarios en términos de adopción de la herramienta. En este sentido, me parece que la preocupación sobre los fenómenos de desinformación, si bien justificada entre algunos sectores de la opinión pública y la academia debido a no pocos ejemplos de manipulación de plataformas en la historia reciente, aunque está presente entre los usuarios de los modelos generativos, no es la principal.
En la parte inferior izquierda del tablero están representados poco más de 3,600 mensajes, una fracción muy pequeña de los casi 220 mil producidos en español en un periodo de cuatro meses y si bien algunos refieren a temas como desinformación, noticias falsas y posibles usos maliciosos de modelos como Chat GPT, la mayoría en realidad señalan “errores” de la máquina: la forma en que ”alucina” al momento de tratar de dar respuesta a una pregunta para la que no tiene información, la producción de autores, títulos y afirmaciones inexistentes en la literatura académica, la incapacidad (temporal, habría que decir) del modelo para ser infalible.
Los usuarios están poniendo a prueba la fiabilidad de la máquina y eso es no solo pertinente sino necesario. ¿Puede ser usado Chat GPT para producir noticias falsas? Por supuesto: es una herramienta sumamente potente que está disponible de forma relativamente accesible (su versión de pago está a la par de algunos servicios de video en streaming). ¿Puede esto exacervar los procesos de polarización que ya vemos en algunos países latinoamericanos? No cabe duda. Pero esto está más relacionado con los propios procesos políticos que en determinadas regiones del mundo se están viviendo que con las características propias de la máquina.
Es decir: sin desestimar los perjuicios que el uso nocivo de modelos generativos de inteligencia artificial pueden producir en determinados contextos sociales, el primer lugar de intervención para evitar estos daños a la salud de las democracias contemporáneas está en los propios contextos de acogida de la tecnología.
El uso de este tipo de tecnologías tiene el potencial de exacerbar las condiciones que se presentan en contextos de polarización pero, como ciudadanía usuaria de este tipo de tecnologías, debemos dirigir nuestros reclamos hacia las fuentes de la polarización y a los actores que se han beneficiado de los fenómenos de desinformación.
Quisiera sostener este argumento a partir de lo que hemos visto que ocurre con otras herramientas como las plataformas de redes sociodigitales: el estudio de los procesos de plataformización ha dado cuenta de cómo cierto tipo de lógicas empresariales, en ocasiones de cariz bastante perverso, inciden en otros espacios sociales como lo son gobiernos y vida cotidiana. Ejemplos hay varios: la negligencia de Facebook en el uso y abuso de nuestros datos ha tenido consecuencias en procesos democráticos de diversos países (Cambridge Analytica), ciertos mercados tradicionales han sido invadidos mediante agresivas e incluso violentas estrategias de cabildeo ante gobiernos en paralelo a prácticas de intrusión de datos y espionaje corporativo (Uber), y las plataformas más populares de red social han sido incapaces para dotar a sus usuarios de herramientas efectivas para combatir la propagación de información falsa y maliciosa, además de para identificar y prevenir distintas formas de violencia digital.
Pero todos estos ejemplos han ocurrido con la connivencia de los poderes establecidos. Los distintos actores políticos han hecho poco y mal trabajo tratando de prevenir el uso malicioso de las plataformas. Aunado a ello, los intentos de regulación muchas veces se dirigen hacia los usuarios, lo que se ha advertido puede atraer un contexto menos democrático en términos de libre expresión. Y es en este tipo de contexto que estamos empezan a adoptar y apropiar los modelos generativos de IA.
Imágenes producidas mediante modelos generativos
Los modelos generativos pueden y seguramente serán usados de forma maliciosa sistemáticamente y esto exige esfuerzos en varios sentidos. Por un lado, se nos plantea un nuevo problema para los procesos de alfabetización digital, como profesionales de la comunicación o académicos debemos proveer a nuestras comunidades de recursos y herramientas que les permitan mantenerse adecuadamente informados y suficientemente alertas para poder identificar flujos de desinformación. Por otra parte, este mismo contexto exige de los actores sociales involucrados una participación más decidida en la producción de contenidos informativos confiables para los grandes públicos. Los medios masivos de comunicación han fallado en ese sentido durante un largo tiempo. No solo han desestimado a sus audiencias sino que se han adaptado poco y mal al nuevo contexto comunicacional… de las últimas dos décadas se podría decir.
Es decir, el uso de este tipo de tecnologías tiene el potencial de exacerbar las condiciones que se presentan en contextos que han sido objeto de procesos de polarización, como lo es México. Pero por alarmante que sea esta posibilidad, como ciudadanía usuaria de este tipo de tecnologías, debemos dirigir nuestros reclamos hacia las fuentes de la polarización y a los actores que se han beneficiado de los fenómenos de desinformación.
Por optimista que pueda parecer, no creo que nos vayan a inundar las noticias falsas. Eso, si ha de ocurrir, falta por verse. Pero si eso ocurre, no será tanto a causa de las cualidades de estas herramientas tecnológicas como por el espírituo con que pueden ser usadas por actores sociales y políticos que sí podemos identificar.
Por último y para poder continuar el diálogo con ustedes, creo que es pertinente decir que en algunos sectores de la academia y los medios, hay una alarma e incluso animadversión hacia los modelos generativos como si estos fueran a acabar con la sociedad como la conocemos. En este sentido, me parece que algunas valoraciones son más que nada normativas antes que basadas en evidencia. Es decir, algunos analistas están poniendo el carro delante de los caballos al tratar de predecir qué ha de ocurrir con las IA.
Estamos en un proceso en el que solo podemos ver una forma temporal de este tipo de herramientas. Con toda seguridad, los modelos generativos cambiarán a formas que aún no nos imaginamos y con probabilidad lo harán muy rápidamente. Piénsese en las redes sociodigitales, en el páramo de actualizaciones desarticuladas que eran a finales de la primera década de este siglo y cómo a fuerza de apropiación colectiva y mutuas contaminaciones entre distintas tecnologías adquirieron la forma con que las conocemos hoy. Las IA (que han estado con nosotros más tiempo del que creemos a primera vista) están empezando su aceleración y en términos de construcción social de la tecnología, estamos tratando de revelar sus controversias como parte del proceso de adopación. La forma en que resolvamos estas inquietudes nos llevarán por un camino u otro. Nuestro deber, desde las Ciencias Sociales, es no perder detalle de este proceso y, creo, tratar de entenderlo para después explicarlo. A la sociedad y a nosotros mismos.
Referencias
Noble, S. U. (2018). Algorithms of oppression: How search engines reinforce racism. New York University Press.
En los últimos años, hemos visto cómo la inteligencia artificial (IA) ha experimentado un auge en el desarrollo y aplicación de tecnologías en diversas áreas, como la medicina, la educación, la economía, entre otras. En este contexto, también se han explorado las posibilidades que ofrece la IA en términos de acción colectiva y movimientos sociales. Es decir, ¿cómo las tecnologías de IA pueden ser una herramienta para la organización y movilización de grupos sociales? En este artículo, analizaremos la importancia de las tecnologías de IA como una posible herramienta para la acción colectiva y cómo la sociología debe prepararse para analizar este fenómeno.
Imagen generada por DALL-E 2. Gente en las calles de la Ciudad de México protestando.
En primer lugar, es importante destacar que las tecnologías de IA se han utilizado en diversos movimientos sociales en todo el mundo, como el movimiento Black Lives Matter en Estados Unidos, el movimiento #YoSoy132 en México o el movimiento #NiUnaMenos en Argentina, entre otros. Estos movimientos han utilizado tecnologías de IA para la organización y movilización de grupos sociales, mediante la identificación y visualización de problemas sociales, la organización de eventos y la promoción de la participación ciudadana.
Uno de los ejemplos más notables de cómo la IA puede ser utilizada como herramienta para la acción colectiva es el caso del movimiento Black Lives Matter (BLM) en Estados Unidos. En un artículo de la revista Scientific American, Kadija Ferryman, investigadora en bioética y justicia social, destaca cómo el movimiento BLM ha utilizado la IA para documentar y visualizar la violencia policial contra la población negra en Estados Unidos. A través de herramientas de IA, el movimiento ha logrado recopilar y analizar grandes cantidades de datos sobre violencia policial, lo que ha permitido identificar patrones de discriminación racial y generar evidencia para sustentar las demandas del movimiento.
Además de la documentación y visualización de problemas sociales, la IA también puede ser utilizada para la organización y movilización de grupos sociales. Un ejemplo de esto es la plataforma de mensajería Telegram, que ha sido utilizada por varios movimientos sociales en todo el mundo, como el movimiento estudiantil en Chile o el movimiento pro-democracia en Hong Kong. En un artículo de la revista Wired, el periodista Matt Burgess destaca cómo el movimiento pro-democracia en Hong Kong utilizó la plataforma Telegram para organizar protestas y evitar la vigilancia del gobierno chino. La plataforma de Telegram utiliza tecnologías de IA para la clasificación de mensajes y la identificación de usuarios, lo que permite a los grupos sociales organizar y movilizar de manera más efectiva a sus miembros.
A pesar de las posibilidades que ofrece la IA como herramienta para la acción colectiva, también es importante destacar que existen desafíos y riesgos asociados con su uso. Uno de los principales desafíos es la brecha digital, es decir, la exclusión de grupos sociales que no tienen acceso a tecnologías de IA o no tienen las habilidades necesarias para utilizarlas. Además, también existen riesgos asociados con la privacidad y la seguridad de la información, ya que la utilización de tecnologías de IA implica la recopilación y procesamiento de grandes cantidades de datos personales.
En conclusión, el uso de las tecnologías de IA muy posiblemente se integrará al repertorio de acción de los actores colectivos en el futuro cercano. Los ejemplos mencionados anteriormente muestran cómo las tecnologías de IA pueden ser una herramienta valiosa para la organización y movilización de grupos sociales, así como para la identificación y visualización de problemas sociales. Sin embargo, es importante tener en cuenta que existen desafíos y riesgos asociados con su uso, por lo que es necesario tomar medidas para garantizar que las tecnologías de IA sean utilizadas de manera ética y responsable.
Desde el punto de vista de la sociología, es importante prepararse para analizar y comprender este fenómeno en su totalidad. Esto implica desarrollar herramientas y conceptos teóricos que permitan analizar los efectos y consecuencias del uso de tecnologías de IA en la acción colectiva y movimientos sociales. Por ejemplo, es necesario desarrollar marcos teóricos que permitan analizar la relación entre la tecnología de IA y la movilización de grupos sociales, así como la influencia de estas tecnologías en la construcción de identidades colectivas y en la participación ciudadana.
En este sentido, algunos autores han propuesto marcos teóricos que permiten analizar la relación entre la tecnología y la acción colectiva. Por ejemplo, en un artículo de la revista Information, Communication & Society, los autores Sergio Roncallo-Dow y Sebastián Valenzuela proponen un modelo teórico que combina la teoría de la acción colectiva y la teoría de la comunicación para analizar el papel de las redes sociales en la movilización social. Este modelo teórico podría ser utilizado como base para analizar el papel de las tecnologías de IA en la acción colectiva y movimientos sociales.
En definitiva, el uso de las tecnologías de IA como herramienta para la acción colectiva es un fenómeno que se encuentra en pleno desarrollo. Si bien existen desafíos y riesgos asociados con su uso, también es importante destacar las posibilidades que ofrece en términos de organización y movilización de grupos sociales, así como para la identificación y visualización de problemas sociales. Desde la sociología, es necesario prepararse para analizar este fenómeno en su totalidad, desarrollando herramientas y conceptos teóricos que permitan comprender los efectos y consecuencias del uso de tecnologías de IA en la acción colectiva y movimientos sociales.
R E F E R E N C I A S
Bennett, W. L., & Segerberg, A. (2012). The logic of connective action: Digital media and the personalization of contentious politics. Information, Communication & Society, 15(5), 739-768.
Gerbaudo, P. (2012). Tweets and the streets: Social media and contemporary activism. Pluto Press.
Roncallo-Dow, S., & Valenzuela, S. (2015). A communication-action model for social media and collective action. Information, Communication & Society, 18(2), 184-206.
Tufekci, Z. (2017). Twitter and tear gas: The power and fragility of networked protest. Yale University Press.
Van Laer, J., & Van Aelst, P. (2010). Internet and social movement action repertoires: Opportunities and limitations. Information, Communication & Society, 13(8), 1146-1171.
Vromen, A. (2017). Digital participation and political consumerism. Routledge.