Esta publicación reproduce un ejercicio realizado como parte del taller “R para Ciencias Sociales” impartido por Brenda Vázquez. A lo largo de este ejercicio se otorgan los enlaces para acceder a las bases de datos y se reproduce el código utilizado para el ejercicio.
El objetivo de este ejercicio es estimar qué tan asociado está el puntaje que obtienen películas de habla inglesa con el número de premios que reciben. La premisa es que aquellas cintas que reciben una mejor recepción de la crítica y la audiencia tienden a obtener un mayor reconocimiento institucional. Usaremos como variable independiente o explicativa el puntaje que obtienen películas de habla inglesa en el sitio Metacritic y como variable dependiente el número de premios recibidos.
Metacritic es un sitio en el que usuarios y sitios especializados valoran distintos tipos de productos culturales (desde películas y series hasta videojuegos y música).
Datos y técnicas
Los datos que utilizaremos para poner a prueba esta premisa fueron construidos por un estudiante originario de India, Syed Mubarak quien publicó en Kaggle una base de datos que contiene 9425 registros de películas y series disponibles en la plataforma Netflix. La base fue publicada en agosto de 2021 por lo que es una de las más recientes. Puede consultarse en el sitio de Kaggle.
El conjunto de datos ofrece 29 variables entre las que se encuentra el título, género, idiomas, duración, entre otros. Para la variable explicativa utilizaremos el puntaje obtenido en Metacritic (“Metacritic Score”) y para la dependiente el número de premios obtenidos (“Awards Received”) que forman parte de la base. Estas variables serán sometidas a un modelo de regresión linear para estimar el efecto que el puntaje tiene en el número de premios. Esperamos que aquellas películas más valoradas por los usuarios sean las que obtengan mayor reconocimiento.
Después de explorar los datos, notamos que existen títulos que no cuentan con datos. Para refinar el proceso, decidimos eliminar los datos perdidos así como aquellos que tuvieran menos de un premio. Como paso adicional, decidimos filtrar los registros para quedarnos únicamente con películas cuyo idioma fuera Inglés. Para llevar a cabo esto realizamos un subconjunto de datos a partir de la base original.
Del total de registros en el conjunto original, redujimos el número de observaciones a 988 películas en habla inglesa con al menos dos premios obtenidos.
Resultados
El siguiente paso fue explorar los descriptivos de cada variable.
summary(metapremios$`Metacritic Score`)
Min. 1st Qu. Median Mean 3rd Qu. Max.
6.0 52.0 66.0 62.9 75.0 99.0
summary(metapremios$`Awards Received`)
Min. 1st Qu. Median Mean 3rd Qu. Max.
2.0 3.0 5.0 12.7 13.0 242.0
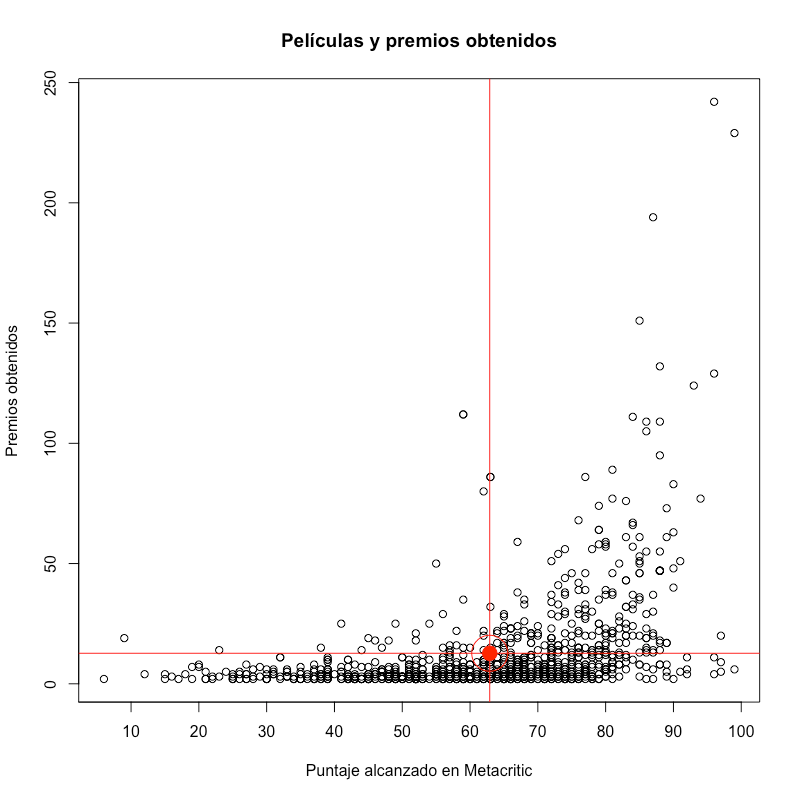
Así, encontramos que la media de puntaje en Metacritic para el conjunto de películas es de 62.9 y la media de premios es de 13 galardones. Mediante las siguientes líneas de código, graficamos los resultados y trazamos las líneas donde se cruzan las medias de cada una de las variables.
Gráfica de dispersión para películas por puntaje alcanzado en Metacritic y número de premios obtenidos.
Lo primero que cabe notar es que, aparentemente, películas con mayor puntaje en Metacritic obtienen un mayor número de premios, sin embargo, aún hay un alto número de películas que obtienen pocos premios pese a su alto puntaje. Cabe esperar que la correlación entre estas dos variables, si bien existe, no sea tan fuerte como esperábamos al principio. Para explorar esto, realizaremos una correlación simple entre ambas.
cor(metapremios$`Metacritic Score`, metapremios$`Awards Received`,
use = “pairwise.complete.obs”)
#[1] 0.3916265
Obtenemos un valor de 0.39 que nos indica una asociación no muy fuerte pero positiva entre el puntaje de la crítica y los premios recibidos. Hemos decidido realizar una exploración gráfica para ver cómo se distribuye la asociación. Para ello, utilizaremos ‘ggscatter’ que requiere instalar y cargar los paquetes ‘ggplot2’, ‘ggsci’ y ‘ggpubr’.
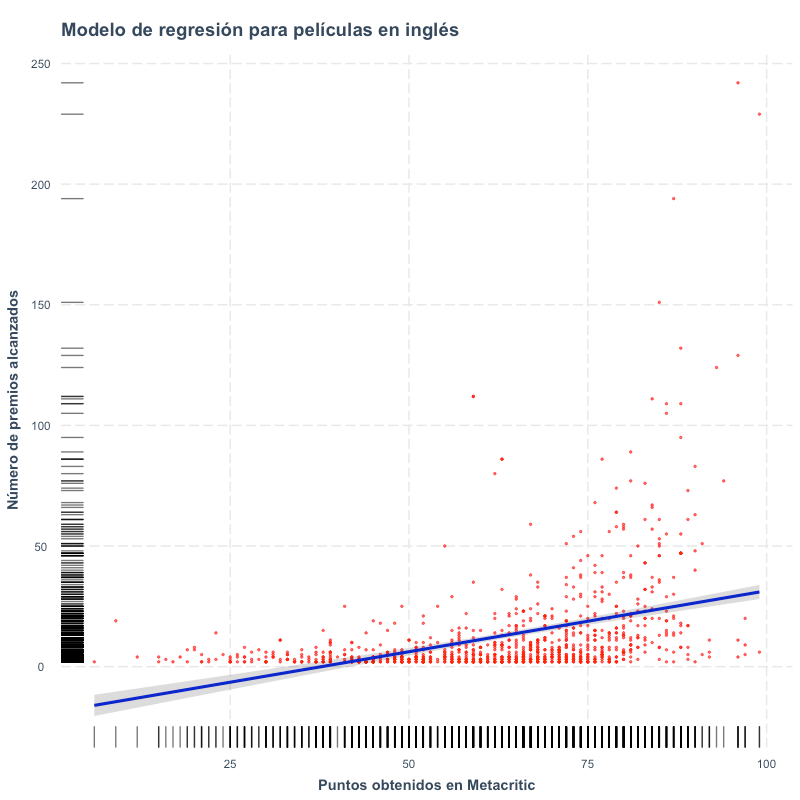
Gráfico de dispersión de la correlación entre Puntaje en Metacritic y Premios Obtenidos para películas en habla inglesa disponibles en Netflix.
Ahora podemos ver no solo el valor de la correlación (R=0.39) sino también su pendiente. Ahora que tenemos certeza de que las variables están asociadas, que su correlación es positiva y que ésta es estadísticamente significativa, procederemos a poner a prueba nuestra premisa calculando un modelo de regresión. Para obtener una versión más estilizada de los resultados del modelo, hemos cargado el paquete ‘jtools’ que nos da la opción summ(modelo) como la veremos a continuación. (La opción con R Base es llamar el resultado con ‘summary(model)’.
Resultados de un modelo de regresión que calcula el efecto del puntaje en Metacritic sobre el número de premios recibidos para películas en inglés disponibles en la plataforma Netflix.
La opción ‘summ(modelo)’ nos ofrece una vista más resumida de los resultados de la regresión. En primer lugar, vemos que el coeficiente del puntaje en Metacritic tiene un efecto positivo que es estadísticamente significativo sobre el número de premios que una película obtiene. El modelo cuenta con una R2 ajustada de 0.15, por lo que, si bien no es el modelo con el mejor ajuste, nos permite explicar el 15% de la varianza de los datos con los que contamos. Cabe señalar que en las exploraciones previas, ninguna otra medida de la crítica (Hiddem Gems Score, Rotten Tomatoes, IMdB Score) obtenían una correlación tan alta como el puntaje en Metacritic.
Como paso adicional, hemos decidido hacer una exploración gráfica de nuestra línea de regresión con ‘jtools’. Aunque la gráfica de correlación ya nos ofrece la visualización, hemos decidido ofrecer esta visualización adicional.
library(jtools)
premios <- metapremios$`Awards Received`
puntaje <- metapremios$`Metacritic Score`
fit <- lm(premios~puntaje)
summ(fit)
effect_plot(fit, pred = “puntaje”, interval = TRUE, plot.points = FALSE, rug=TRUE,
partial.residuals = TRUE,
point.size=0.5,
main.title = “Modelo de regresión para películas en inglés”,
x.label = “Puntos obtenidos en Metacritic”,
y.label = “Número de premios alcanzados”,
colors = “blue2”,
point.color= “red”)
Gráfico de dispersión del modelo de regresión para películas en inglés disponibles en la plataforma Netflix. El puntaje obtenido en Metacritic tiene un efecto en el número de premios alcanzados.
Discusión
Resulta difícil estimar qué película recibirá una mayor cantidad de premios únicamente tomando en cuenta la percepción que la crítica ofrece. Metacritic es un espacio para que usuarios valoren aquellos filmes que más les complacieron, la plataforma permite no solo colocar un número a las cintas sino también ofrecer una reseña. En este sentido, como plataforma social, sintetiza parte del sentimiento que las audiencias tienen en torno a una producción cinematográfica en particular y a la industria del cine en general.
En ese sentido, el puntaje en Metacritic nos ha servido como una variable de aproximación (proxy) a un elemento que puede tener impacto en el éxito final, medido en número de premios, que tiene una película.
El modelo de regresión, con su R2=0.15 nos lleva en la línea correcta al poner a prueba el efecto de una variable que podría explicar, en parte, el éxito de una producción cinematográfica. En este caso, hemos limitado el cálculo a cintas en habla inglesa que se encuentran en una plataforma, Netflix, por lo que no sabemos nada de aquellas cintas fuera de la plataforma, pero creemos que esta muestra nos da pistas del fenómeno.
Otra caución a tomar en cuenta es que un modelo de regresión linear puede no ser tan indicado para evaluar el efecto que la crítica tiene en las películas. Es posible que, si exploramos la asociación entre estas dos variables tomando en cuenta el género del filme, obtengamos resultados más robustos para cierto tipo de filmes (drama, comedia, acción, etc.), por lo que necesitamos seguir explorando los datos integrando variables de otro tipo (categóricas) con un modelo ajustado a las mismas.
Conclusiones
Este ejercicio ha buscado poner a prueba la idea de que el peso de la crítica tiene cierto efecto en el reconocimiento que un filme logra. Así, hemos visto que la calificación que las audiencias ofrecen a una película está asociado positivamente con el número de premios que ésta recibe.
Al calcular un modelo de regresión, hemos podido estimar el efecto que buenas calificaciones llegan a tener en producciones cinematográficas. Hemos usado una base disponible y que cuenta con cintas disponibles en una plataforma de VOD. De contar con un mayor número de datos, es posible que podamos confirmar esta premisa y, si estimamos modelos que puedan integrar variables categóricas, también es posible que podamos discernir el efecto entre distintos tipos de películas.
De momento, hemos logrado explorar la posibilidad de bases de datos de este tipo en el ánimo de utilizar herramientas de estadística y visualización de datos para estimar analíticas culturales, un área en la que creemos que es necesario diseñar aproximaciones sistemáticas que nos permitan construir una mejor comprensión de los fenómenos culturales contemporáneos.
Publicado originalmente en Medium el 17 de marzo de 2020
La pandemia por COVID-19, la variante de coronavirus que surgió en Wuhan, China a finales de 2019, ha inundado la conversación digital. En México, la producción de mensajes en torno al “coronavirus” ha mantenido una serie de hashtags entre los “trending topics” de los últimos días debido, principalmente, a las noticias de nuevos casos y a las medidas implementadas por las autoridades con miras a contener el contagio.
El 11 de marzo, la OMS declaró el brote de COVID-19 como una pandemia y en México el tema colocó a dicha palabra, “pandemia” como uno de los TT durante aquella jornada. En México, según la estimación del encargado de la crisis sanitaria, el subsecretario de Salud, Hugo López-Gatell, nos esperan 12 semanas con este tema. Mientras distintas medidas se toman en el país (al igual que en otros países) y el número de pacientes en México pasó de 53 a 82 el día 17 de marzo, las y los usuarios de Twitter mantienen activa la conversación respecto al tema.
A partir de dos extracciones de datos de la red social Twitter, buscamos evaluar dos cosas: ¿hacia quién se dirigen las interacciones en el marco de la contingencia por COVID-19? y por otra parte, ¿entre quiénes se entrelaza la conversación digital?
Lo que sigue a continuación son visualizaciones e interpretaciones muy someras de datos, exploratorias en primer lugar pero que buscan hacer un poco de sentido a cómo los usuarios usan las redes en momentos de incertidumbre.
Información, ansiedad y duda de alta exposición
A pesar de la existencia de canales institucionales de información (conferencias de prensa diarias y emisión de boletines informativos), se han dado fenómenos como las compras de pánico en algunos lugares de México o difusión de noticias falsas, tanto por medios como WhatsApp como desde las cuentas personales de periodistas.
Ante ello, la primera pregunta que nos surgió es hacia quién se está dirigiendo la conversación digital en redes sociales, en particular Twitter, en el marco de la crisis por COVID-19 o coronavirus en México.
Dado que existen múltiples hashtags en uso para referirse a la pandemia (#covid19, #covid-19, #covid19mx, entre otras variantes) decidimos dejar de lado la idea de extraer mensajes mediante un hashtag. En su lugar usamos una palabra clave, simple pero presente en casi todos lados: “coronavirus”.
La siguiente dificultad era el hecho de que esta palabra está presente tanto en los mensajes en español (en toda Latinoamérica) como en inglés en el resto del mundo. Para tratar de filtrar lo más posible la búsqueda, decidimos captar los mensajes geolocalizados alrededor del centro de México.
Adicionalmente, decidimos dejar fuera los retweets de la primera muestra. La premisa era sencilla: en un primer momento, no nos interesan las interacciones como quién está siendo referido en los mensajes que hablan del tema.
A partir de este triple criterio (palabra clave + geolocalización + mensajes únicos) realizamos una extracción de publicaciones de Twitter mediante R Studio. El resultado fueron 108 mil mensajes únicos publicados entre las 20 horas del 12 y las 11 horas del 17 de marzo, aproximadamente.
Extracción de mensajes únicos en Twitter
Llamamos “mensajes únicos” a los que se visualizan a continuación, ya que descartamos de la extracción aquellos que son retweets y captamos solo publicaciones independientes entre sí. Esto reducirá la cantidad de relaciones entre el total de los usuarios obtenidos, pero nos permitirá observar a quién se dirigen (si acaso) sus mensajes en forma de menciones y replies.
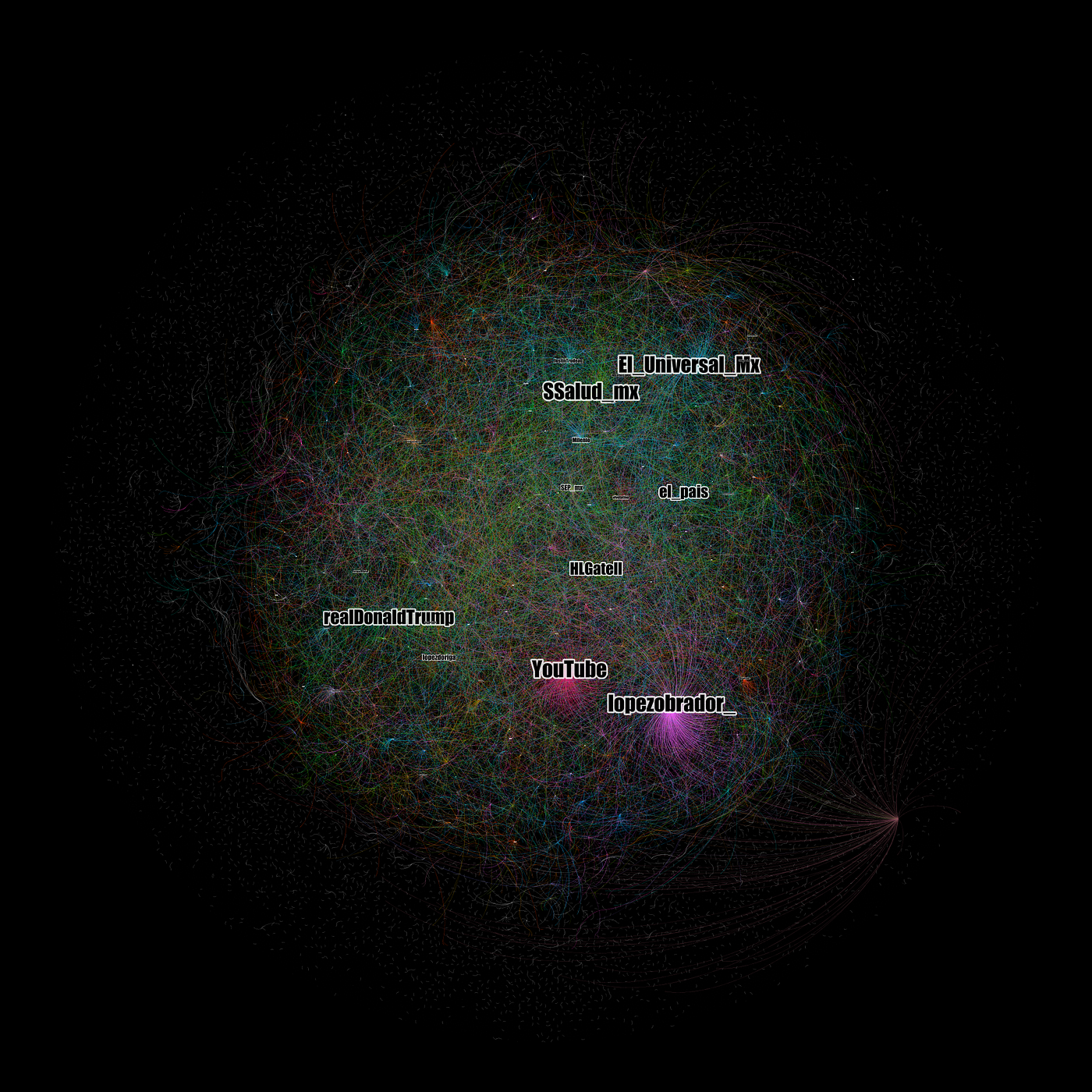
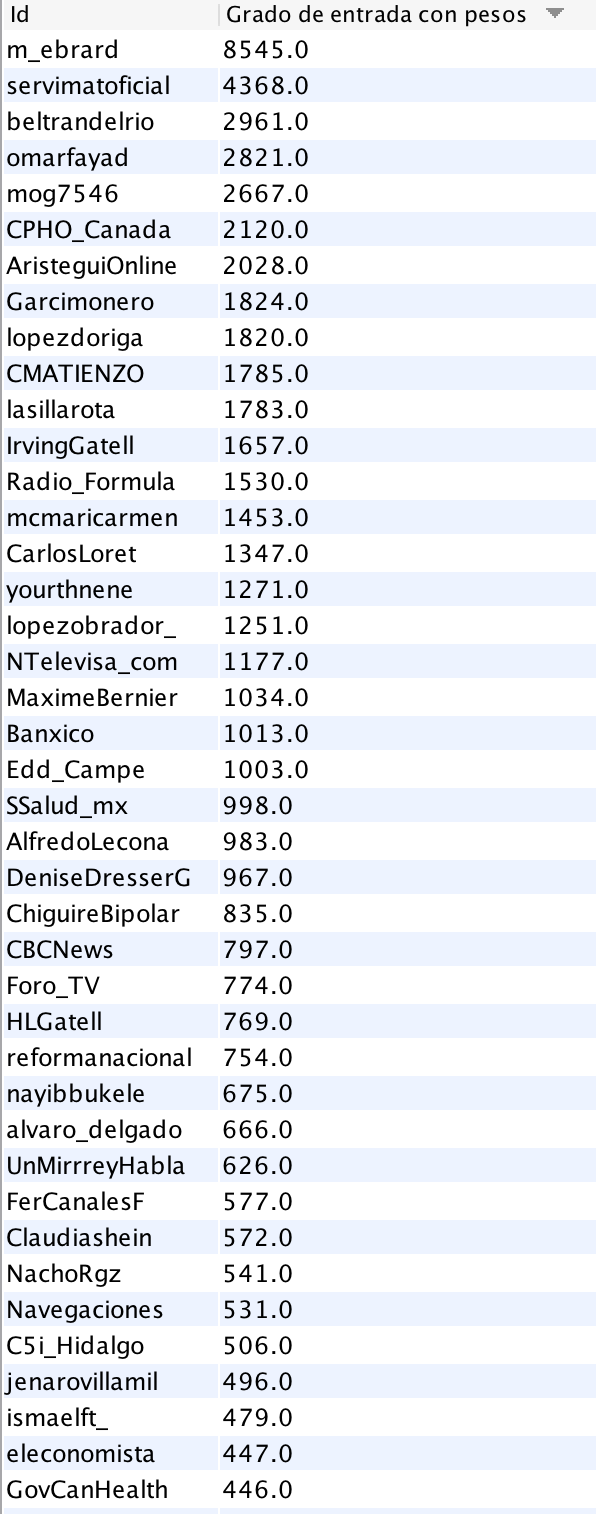
Grafo 1. Red usuario-a-usuario a partir de 108 mil mensajes únicos publicados en Twitter (18/03/2020) geolocalizados en México a partir de la palabra clave “coronavirus”. La visualización se construyó mediante el algoritmo Force Atlas 2 de Gephi, las etiquetas de nodos destacan aquellos con mayor grado de entrada con pesos.
La red U2U está conformada por 56,821 nodos y 26,450 aristas. Al haber descartado los retweets es de esperar contar con una red “menos conectada”. En el Grafo 1 se visualizan los nodos con mayor grado de entrada. Son usuarios que recibieron mayor número de menciones o respuestas en la red. Además de la cuenta del presidente de México, Andrés Manuel López Obrador (@lopezobrador_) se encuentran la cuenta oficial de la Secretaría de Salud y la del subsecretario de esa dependencia, Hugo López-Gatell.
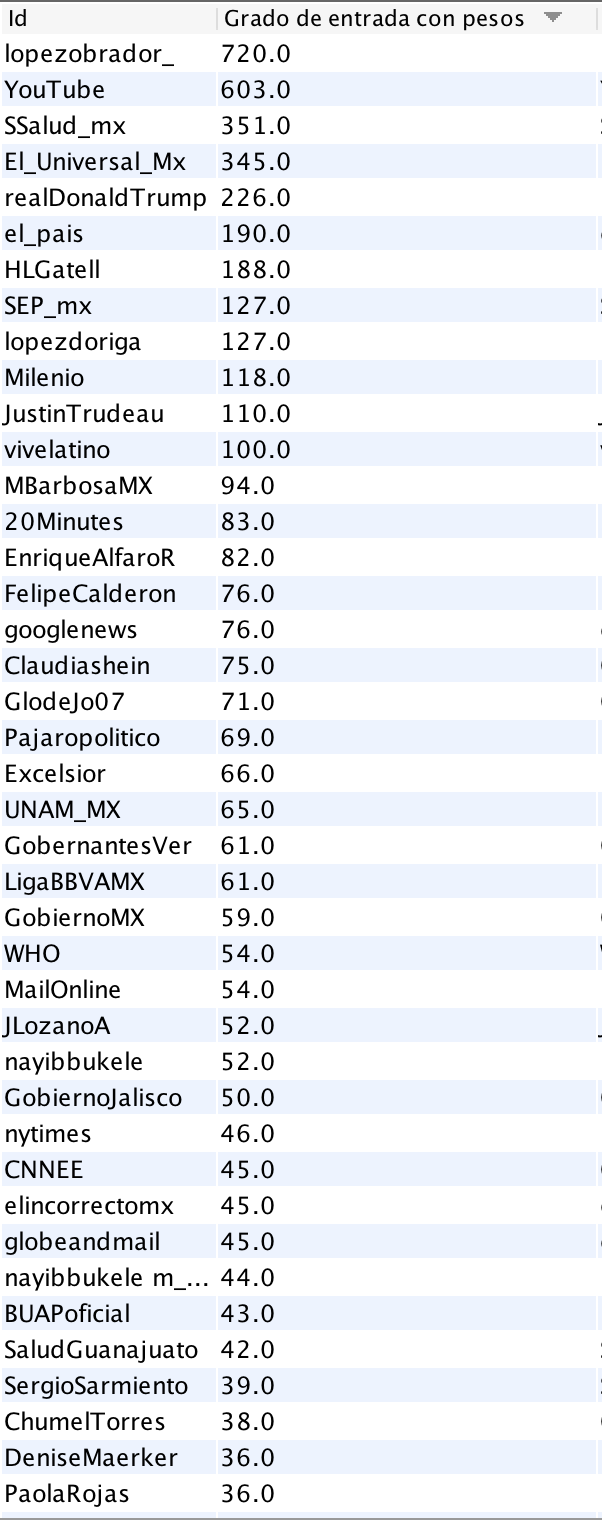
La cuenta de dos medios, El Universal y El País, se encuentran entre los nodos con mayor número de relaciones de entrada. También se encuentra el servicio de video YouTube y la cuenta del presidente de Estados Unidos, Donald Trump (@realDonaldTrump). Otras cuentas que se volvieron centrales fueron la del periodista Joaquín López Dóriga, la del ministro canadiense Justin Trudeau, y la cuenta del festival musical Vive Latino que se realizó el fin de semana previo pese a las críticas y dudas en medio de la crisis de COVID19. Para tener una mejor idea de aquellos nodos más centrales (por in-degree), los ubicamos en la tabla que nos ofrece Gephi.
Tabla 1. Nodos con mayor grado de entrada en el Grafo 1.
Entre los usuarios hacia los que más se dirigieron mensajes en la muestra de mensajes únicos se encuentran periodistas, autoridades y medios de comunicación. Al haber descartado los retweets de la extracción, solo captamos los mensajes dirigidos y menciones hacia estos usuarios. No exploramos en el campo de “text” de las publicaciones por lo que no aventuramos el sentido (positivo/negativo) de las publicaciones.
Una posible forma de interpretar este patrón podría ser la siguiente: al observar mensajes únicos (descartando RTs) en Twitter en torno al tema de la pandemia por coronavirus en México, vemos que gran cantidad de los contenidos se dirigen a autoridades, personajes políticos y medios. Así, es posible que los usuarios estén dirigiendo dudas o reclamos a esos nodos más centrales.
El método de extracción que elegimos en esta primera fase nos da redes más desconectadas. Una prueba de ello es observar de nuevo el Grafo 2 pero destacando los nodos por grado de salida. Así vemos una gran cantidad de nodos desconectados del resto de la red que “orbitan” a aquellos sectores más conectados. Estos “satélites” son usuarios que, aun cuando usaron la palabra clave de nuestro criterio de búsqueda, no mencionaron ni respondieron a otros usuarios en esta muestra.
Grafo 2. Red usuario-a-usuario, los nodos se destaca por su grado de salida.
Extracción de mensajes incluyendo retweets
Cuando cambiamos el método de extracción y aceptamos captar los retweets tendemos a obtener una red más conectada. Los retweets parecen expresar cierto grado de connivencia con el mensaje del autor. Esta relación positiva entre usuarios se suma a las menciones y respuestas, que pueden tener otra cualidad.
Sin embargo, lo que sí parece representarse de manera más coherente son las “comunidades” de usuarios que se forman en torno a ciertos temas o a otros usuarios. La ventaja de incluir los retweets parece ser la de dar mayor cohesión a aquellos usuarios que comparten más “espacio digital” en una muestra de tweets dada.
El Grafo 3 representa las relaciones de usuario-a-usuario para una muestra de 107 mil mensajes en la red social Twitter, publicados entre las 20 horas del 16 y 11 horas del 17 de marzo, aproximadamente. El grafo resultante cuenta con 72,258 nodos y 94,037 aristas. Es notable que abarca menos tiempo, esto debido a que absorbimos el impacto de los retweets.
Grafo 3. Red de usuario-a-usuario a partir de 107 mil mensajes en el servicio Twitter, geolocalizados en México y a partir de la palabra clave “coronavirus”. Las etiquetas de nodo más grandes expresan a los usuarios con mayor grado de entrada.
El patrón que muestra el nuevo Grafo 3 al incluirse los RTs es muy distinto al del primer grafo. En primer lugar, podemos notar que a pesar de que existe un gran número de comunidades (en una publicación anteriores notamos la polaridad en la discusión digital cuando usábamos un criterio de búsqueda por hashtag: Redes a favor y en contra de AMLO en México), la vinculación entre ellas es de “poca fuerza” y mantiene a los islotes de usuarios entremezclados en algunas zonas y separados en islas en otras. La lista de usuarios más centrales por grado de entrada es ilustrativa en este sentido.
Tabla 2. Usuarios con mayor grado de entrada en el Grafo 3 que incluye relaciones de retweet.
Aunque siguen apareciendo autoridades y periodistas, a la lista se unen youtubers, medios alternativos e incluso cuentas “de humor”.
Una forma de interpretar este patrón es que, además de la información oficial en torno al tema que aquí nos ocupa, la pandemia por coronavirus presente en México, otras formas de interpretar el fenómeno están activas en la conversación además de la información oficial y la interpelación entre actores políticos, que muchas veces ocupan gran parte de los análisis.
Otra cosa a considerar es que el método de extracción nos ofreció un panorama más heterogéneo en torno al tema del coronavirus. Creemos que en ocasiones, el uso de hashtags para generar grafos nos impide ver a ciertos usuarios. Encontrar la manera de salvar estos sesgos no es fácil ni creemos aquí haber logrado algo por el estilo. Pero sí creemos que utilizar una palabra clave y la geolocalización de mensajes en lugar de una etiqueta cambia la forma de los patrones encontrados en los grafos. Para el caso que aquí expusimos, la poca conectividad interna de la red nos resultó llamativa y expresiva de una heterogeneidad en la conversación. Por ejemplo, cuando sometimos el grafo a un filtro de conectividad k-core (k=2) nos quedamos con apenas el 25% por ciento de los nodos y el 49% de las aristas. Cuando elevamos k=3 nos quedó poco más del 9% de los nodos y 27.5% de las aristas. Es decir, una gran sección del grafo está muy poco conectada entre sí y al resto de los nodos, a pesar de captar las relaciones de retweet.
Posibles consideraciones al momento de analizar datos de Twitter
Como se puede adivinar, esta exploración de datos está lejos de proponer conclusiones. Pero sí algunas consideraciones al momento de analizar datos extraídos de Twitter.
La primera es que los datos con que trabajamos, como con cualquier otra estrategia de investigación, están lejos de ser precisos. Aunque usamos operadores para geolocalizar mensajes de Twitter esperando obtener solo publicaciones de México, estuvimos lejos de lograr el objetivo. Algunas publicaciones de usuarios fuera del país cayeron en la muestra.
Otra observación es que, al descartar un tipo de las relaciones posibles entre usuarios (en la primera muestra, el retweet) los patrones que se nos presentan son muy distintos a cuando sí la tomamos en cuenta. (Sin contar el sesgo temporal que se nos podría presentar: en la primera muestra, captamos más días que en la segunda) Esto implica que podemos cambiar las preguntas que hacemos a los datos a partir de cómo integramos o dejamos de lado ciertos tipos de relaciones susceptibles de observarse.
Finalmente, que dando estas pequeñas vueltas de tuerca, podemos pasar de un problema a otro muy distinto. Aquí apenas quisimos sugerir hacia dónde y quién se está dirigiendo la conversación digital en el tema del coronavirus y cómo cambia la perspectiva si se integra o descarta un tipo de relación posible. Mientras reflexionamos al respecto, quizá se nos ocurran nuevas preguntas qué formular a los datos.
El presidente Andrés Manuel López Obrador presentó su informe con motivo al primer año de gobierno. En el marco de su mensaje, aseguró haber cumplido 89 de 100 compromisos establecidos como metas de su primer año de gestión. Sin embargo, su informe se presenta ensombrecido por el aumento de la violencia del crimen organizado que ha dejado 33 mil personas asesinadas en lo que va de su administración, la paralización del crecimiento económico y duras batallas políticas como la designación de la titular de la Comisión Nacional de Derechos Humanos, las idas y venidas con el gobierno estadounidense de Donald Trump, la movilización de activistas como la familia LeBarón y Javier Sicilia, y la controversia por el asilo político otorgado al presidente de Bolivia, Evo Morales.
Prácticamente, todas las coyunturas del “primer gobierno de izquierda mexicano” han sido acompañadas por explosiones de activación digital en servicios de redes sociales, en especial, Twitter. Diversos analistas han señalado la presencia de redes tanto a favor como en contra del presidente López Obrador que han participado en un intenso debate con signos de polarización.
Las redes sociodigitales han sido el escenario en el que múltiples voces se han hecho escuchar, las usuarias y usuarios han construido “paisajes” y foros de los que se ha apropiado para las más diversas movilizaciones de reclamos y discursos. Tan sólo en el último año, eventos tales como el #MeToo mexicano, las coyunturas producidas por hechos violentos como el ataque en Minatitlán (Signa Lab) o las propias elecciones de 2018 con el esfuerzo de #VerificadoMX han dejado constancia de los espacios de imaginación, posibilidad y disputa que se generan en “las redes”.
Sin embargo, también se han hecho visibles nuevas lógicas que parecen buscar la desapropiación de estos nuevos espacios.
De ahí que cada vez sea más necesario ver con precaución lo que ocurre en la “esfera digital” para no tomar las producciones culturales de estos espacios como si fueran un simple reflejo del estado de ánimo de la ciudadanía. Hay solapamientos entre ambos espacios, el digital y “analógico”, pero la construcción de las distinciones requiere cierto distanciamiento.
El laboratorio de investigación de ITESO Guadalajada, Signa Lab, señaló en un breve informe algo que puede parecer obvio pero en lo que cabe la pena detenerse: “internet no es una sustitución del espacio público ni de las prácticas políticas, sino un escenario de rearticulación de los repertorios comunicativos y políticos” y las nuevas dinámicas producidos desde y hacia el poder “constituye una muestra de cómo la lucha por los regímenes de verdad y la «producción» de lo político en los entornos digitales ha entrado en una fase marcada por los procesos de automatización”.
La discusión sobre la presencia de automatismos y bots en la discusión política digital es importante pero, creemos, no lo es todo. Lo que la discusión digital parece presentarnos son aparentes “cajas de resonancia” que podrían interpretarse como polarización. Sin embargo, ¿a qué grado existe polarización sin diálogo? ¿Qué vasos comunican las líneas del debate digital? O, si no llegamos a precisar estas cuestiones, valdría quizá la pena saber ¿de qué están hablando esas esferas distantes pero necesariamente conectadas que se juegan el todo por el todo en un “con nosotr*s o con ell*s”?
AMLO: Primer año, informe y marchas
Para tratar de ensayar una respuesta a esta última pregunta hemos realizado una extracción de mensajes de la red social Twitter durante el día 1 de diciembre de 2019. La extracción se realizó de las 12:00 a las 18:00 horas obteniéndose un total de 115,632 tweets. El criterio de selección fueron dos etiquetas o hashtags “antagónicos” en la conversación digital: #amlofest y #marcha1dediciembre. Las etiquetas fueron elegidas por ser las que ocuparon los primeros lugares en los Trending Topics de México durante la hora posterior al inicio del informe por el primer año de gobierno de Andrés Manuel López Obrador y la marcha realizada por opositores que partió del Ángel de la Independencia al Monumento a la Revolución, ambos eventos, en la Ciudad de México. (Los tweets fueron recuperados mediante R Studio utilizando la librería “rtweet”, las visualizaciones fueron realizadas con la paquetería Gephi. Todos los grafos recibieron el mismo tratamiento: el algoritmo de distribución fue Force Atlas 2, las etiquetas tienen tamaños proporcionales para medidas de grado con pesos).
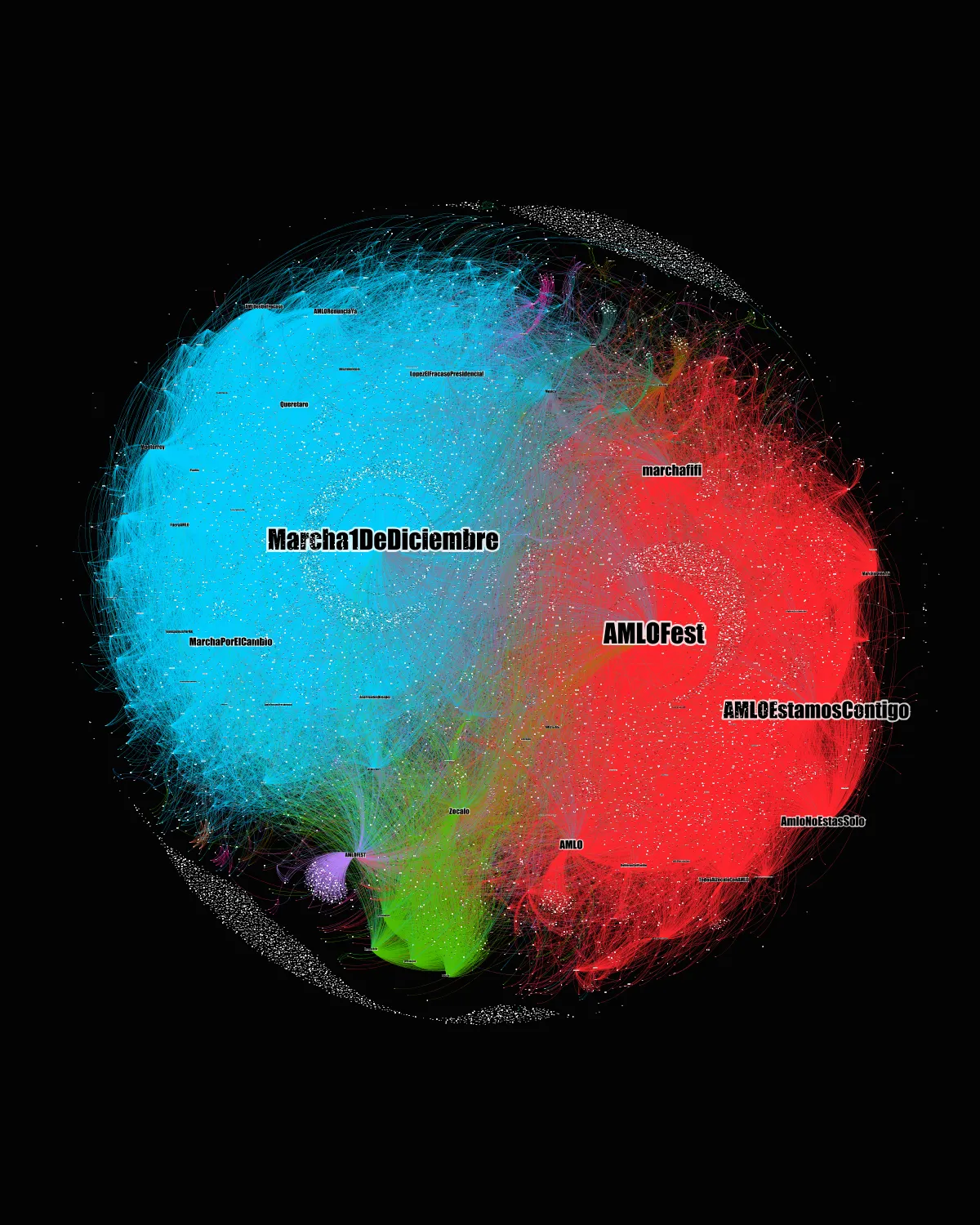
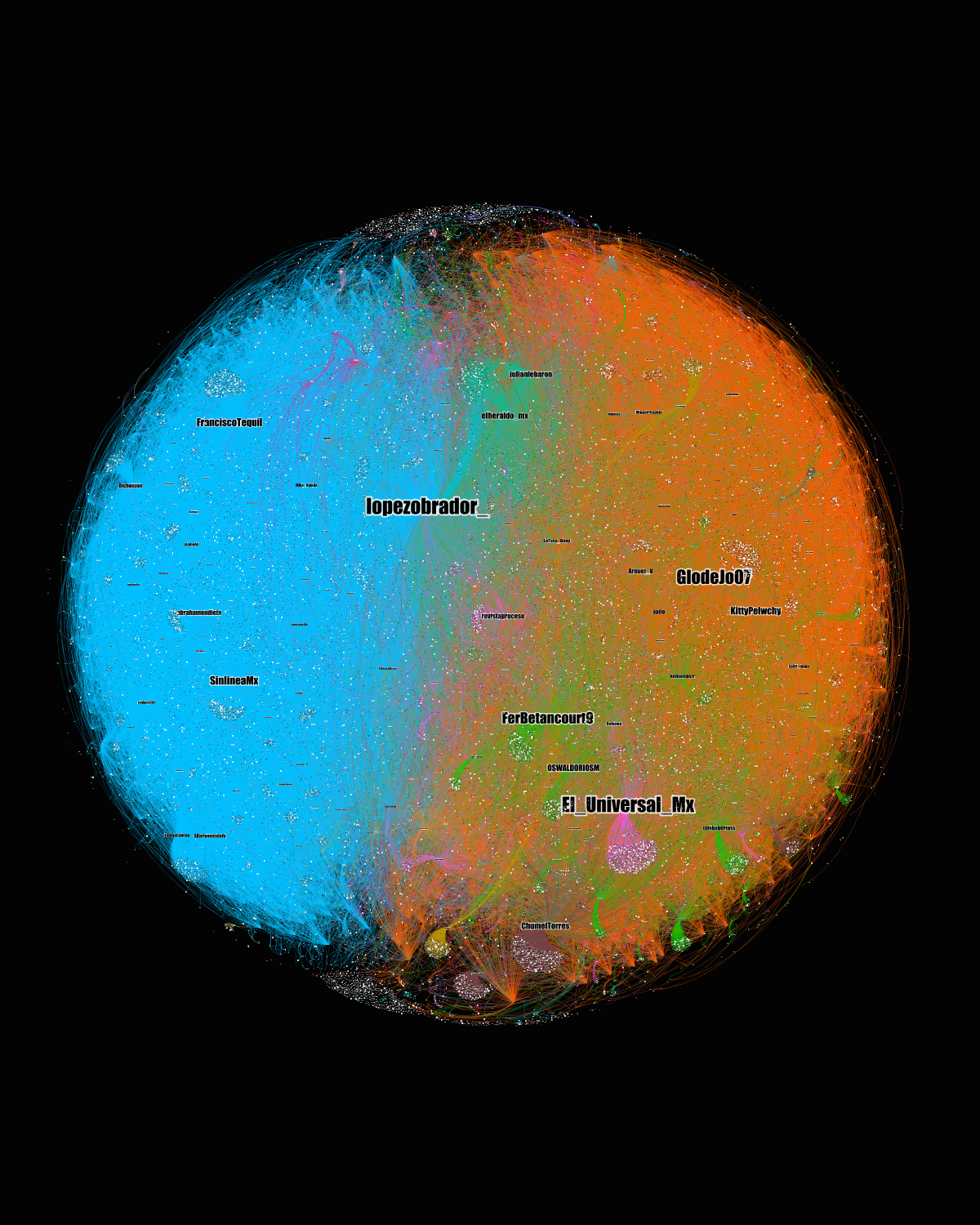
El Grafo 1 visualiza las relaciones entre usuarios (red usuario-a-usuario — menciones, retuits, favoritos — ) para los mensajes que conforman la muestra. Los nodos se encuentran escalados por grado de entrada por lo que las etiquetas de nodo más grandes muestran a los usuarios a los que se dirigieron mayor número de mensajes en la muestra. La red cuenta con 33,729 nodos y 115,590 aristas (Av. Degree: 3.42, Av. Path Lengh: 7.26). El cálculo de modularidad dio como resultado 1,432 comunidades (Res: 1, Modularity: 0.46).
Grafo 1. Red de usuario a usuario para las etiquetas #amlofest y #marcha1dediciembre. Nodos: 32,729. Aristas: 115,590. Los nodos están representados por mayor grado de entrada con pesos.
Básicamente, se forman dos grandes comunidades. La azul, en la que la cuenta @lopezobrador_ cuenta con el mayor grado de entrada, representaría una comunidad “pro-AMLO” mientras que la comunidad naranja representaría la red “Anti AMLO” en la que, además de la cuenta del medio El Universal, otras dos cuentas presentan alto grado de entrada. Se trata de las cuentas @FerBetancourt09 y @GlodeJo07. Estas cuentas aglomeran un gran número de retweets y favoritos. A continuación se muestran dos de los mensajes con mayor número de interacciones en la red.
Andan escribiendo por todos lados que la “marcha es pedorra”, que “puro pendejo va”, que “junta mas gente un perro atropellado”. A ver,si tan pedorra es la marcha ¿por qué les preocupa tanto que andan desesperados por desacreditarla? La oposición ya se unió ❤️#Marcha1DeDiciembre
La sola presencia de usuarios con alto nivel de entrada en una red, sea esta a favor o en contra de un personaje, no otorga por si misma evidencia de automatismos o coordinación. Para ello, sería necesario analizar más a detalle a los usuarios que interactúan en sendas redes. No es ese el objetivo de este pequeño ensayo. Sino el contenido de los discursos circulantes “entre” las comunidades.
Para ello, el siguiente paso fue realizar un grafo de los hashtags usados por los usuarios (usuario-a-hashtag). El resultado fue una red con 20.924 nodos y 54,427 aristas (Av. Degree: 2.6; Av. Path Lenght: 1) cuyo cálculo de modularidad dio como resultado 3,998 comunidades.
Una forma de interpretar lo anterior podría ser la siguiente: si bien hemos extraído mensajes a partir de dos etiquetas o palabras clave, los usuarios utilizan una gran variedad de hashtags en su producción; no obstante ello, es posible que ciertas etiquetas tiendan a “agruparse” y son esos pequeños clusters de palabras clave las que nos dan una pista sobre la cualidad del discurso que cada red estaría movilizando.
El Grafo 2 muestra estas relaciones. Las etiquetas tienen tamaños proporcionales para grado con pesos. Aunque ahora parece haber más comunidades en juego, hay dos principales que atraen nuestra atención.
Grafo 2. Red de usuarios a hashtags. Los etiquetas de nodo con mayor tamaño expresan su grado con pesos dentro de la red.
En la comunidad azul (ahora “Anti AMLO”) la etiqueta principal es la que guió parte de nuestra búsqueda, #marcha1dediciembre, pero a esta se asocian con cierta importancia hashtags tales como #marchaporelcambio, #lopezelfracasopresidencial y #amlorenunciaya, entre otras.
En la comunidad roja (“Pro AMLO”) el peso de las etiquetas está más distribuido no solo entre la principal, #AMLOfest, sino que le sigue #AMLOnoestassolo, #AMLOestamoscontigo y #marchafifi. En cuanto a la segunda y tercera, tienen cierta similitud con las que se han presentado en otras coyunturas impulsadas por la denominada RedAMLOve (Signa Lab).
Para algunos autores, el uso de hashtags forma parte de la estrategia de estas redes digitales para visibilizar sus mensajes, aglomerar a los adherentes y establecer las pautas del discurso que producen (Blevins et al, 2019) y es de esperarse que entre las etiquetas se dé cierto grado de homofilia (Xu y Zhou, 2020) o en nuestros términos, que la afinidad entre los miembros de una red dé como resultado un uso más “coordinado” de las etiquetas.
Es en las relaciones entre las etiquetas donde creemos que se dan algunas pistas de cómo se da el diálogo, si alguno, entre las redes de activación digital, en este caso, a favor y en contra de un tema o personaje político.
Mañana se cumple un año del inicio de una transformación del país que debe iniciar c un cambio personal. Al zócalo #Amlofest. Por un trabajo a favor del todo.
Redes antagónicas, esferas desconectadas: el debate sin diálogo en torno a AMLO
El último paso que seguimos fue graficar las relaciones entre etiquetas. El grafo por sí mismo no nos da mucha más información, pero es necesario visualizarlo para ver cómo se distribuye el discurso digital cuando solo de hashtags se trata.
El Grafo 3 contiene 1,373 hashtags representados por nodos entre los cuales existen 2,943 relaciones o aristas (Av. Degree: 4.3). El cálculo de modularidad (0.45) dio como resultado 56 comunidades.
Grafo 3. Relaciones entre hashtags que conforman la muestra. Nodos: 1,373. Aristas: 2,943.
A partir de este grafo se realizó un sub-selección de etiquetas. Para ello, se utilizó el filtro de conectividad K-Core (k=5) (El filtro de conectividad K-Core es una de las opciones de filtrado que ofrece el software Gephi y permite obtener los nodos más conectados a la red. A mayor profundidad del filtro, menos nodos quedan en el grafo, pero manteniéndose siempre los que cuentan con mayor número de relaciones. Así, el filtrado nos permite “ver” a aquellos nodos que “sostienen” la red). El resultado dejó un total de 146 nodos (que representan el 10.6% del total) y 1,026 relaciones entre los mismos (34.86%).
Lo que este tipo de filtro deja ver, intuitivamente, es que solo 10% de los hashtags están presentes en más de una tercera parte de las relaciones. Es decir, obtenemos las etiquetas más utilizadas por los usuarios pero, a la vez, las más relacionadas entre sí.
Una vez obtenida esta lista de etiquetas, hemos decidido categorizarla. Para ello, partimos de dos categorías propuestas por Blevins et. al (2019) quienes señalan que los hashtags suelen representar ya sea la posición que toman los usuarios o la interpretación de estos sobre los eventos con los que entran en relación. Así, el primer tipo de hashtags serían marcadores ideológicos mientras que los segundos, representan el grupo de marcadores conceptuales.
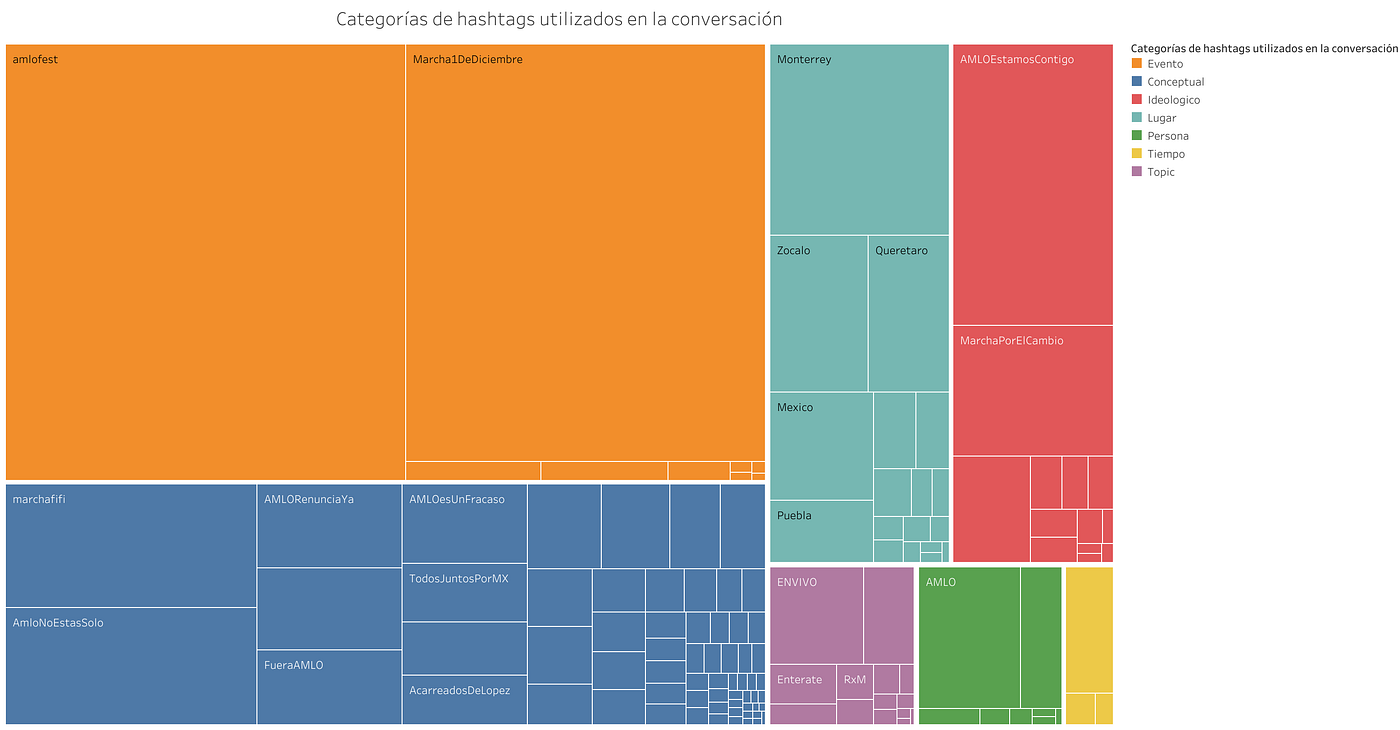
Adicionalmente, al estudiar la lista de hashtags hemos decidido añadir nuevas categorías: primero, separamos aquellas etiquetas que refieren al Evento “en sí”, y que representan nuestros criterios de búsqueda; separamos también las etiquetas que hacían referencias a lugares, a personas, a fechas o momentos del día y una última categoría que denominamos “Topic” para aquellos temas que se salían de la discusión o que referían a temas específicos.
Distribución de los hashtags utilizados por los usuarios que conforman la muestra. El tamaño de los cuadros de hashtag expresa su grado con pesos dentro de la red HT2HT.
Las etiquetas de Evento (15) representan el 10.3% del total de hashtags utilizados. Las que conforman la mayoría del discurso son los marcadores Conceptuales (70 hashtags, 48% del total). El resto son los marcadores Ideológicos (13 HT’s, 8.9%), de Lugar (20 HT’s. 13.7%), de Tópico (15 HTs, 10.3%), de Persona (10 HTs, 6.8%) y Tiempo (3 HTs, 2%).
Si seguimos lo hasta aquí expuesto, la mayor parte de los mensajes que conforman la muestra, al utilizar marcadores conceptuales, estarían produciendo un discurso que busca interpretar o “enmarcar” la coyuntura política de la que están participando.
Por “enmarcamiento” nos referimos a los marcos interpretativos a partir de los cuales un grupo busca hacer sentido tanto de su acción como de los eventos, y esta definición de intereses se da en contraposición a otros grupos (Treré, 2015).
Lo anterior nos parece importante porque, lo que intenta ensayar esta respuesta es: que dado que parecen existir dos esferas en discusión, luchando por la definición del espacio político digital, la forma en que buscan enmarcar (o dar significado a) los eventos importa por lo que propone tanto a sus adherentes como a los públicos de esta conversación.
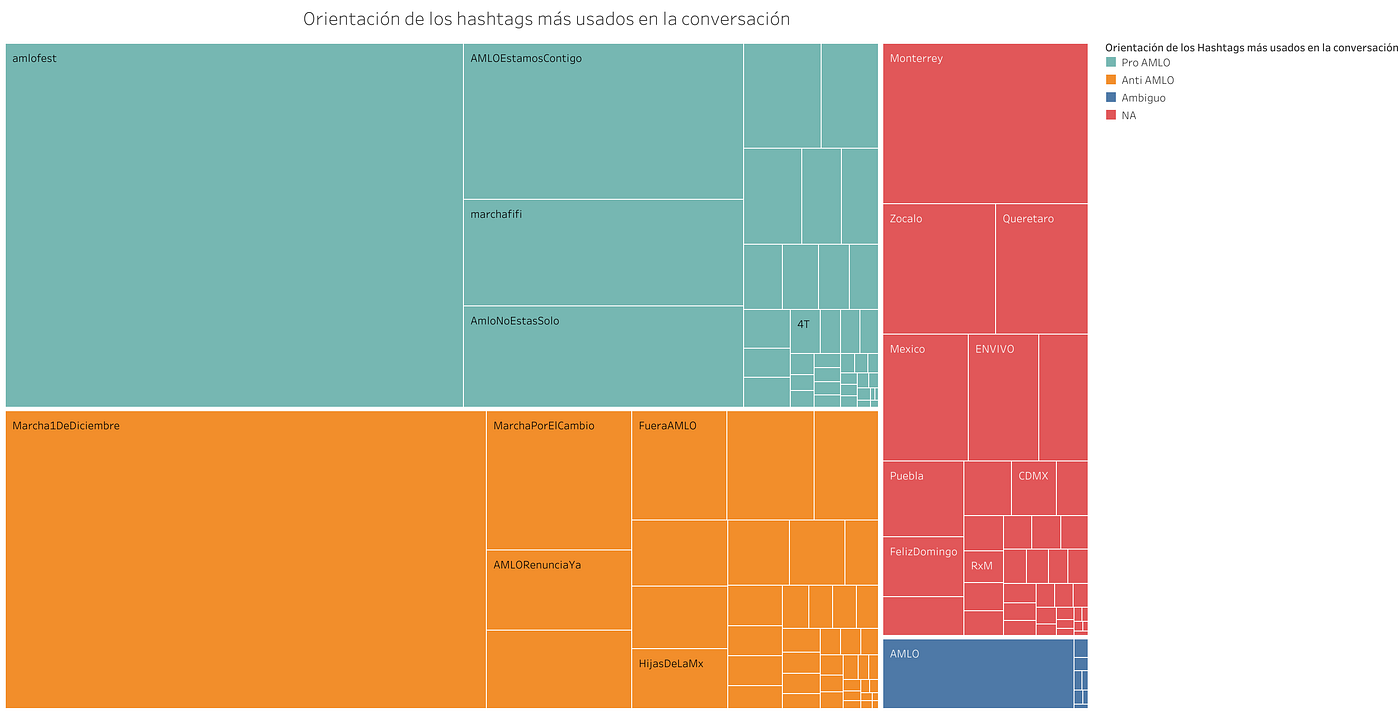
¿Cómo proponen estas redes antagónicas el discurso digital? Para tratar de hallar pistas al respecto hemos vuelto a categorizar las etiquetas obtenidas, esta vez, definiéndolas como parte de un discurso “Anti AMLO” y uno “Pro AMLO”. Esta decisión, un tanto arbitraria, solo intenta seguir la línea que los mensajes sugieren. No es una definición normativa como guiada a la vez por los datos y por el criterio analítico que aquí hemos seguido.
Del total de etiquetas, 47 se clasificaron como “Anti AMLO” (32.2%) mientras que 48 cayeron en la categoría “Pro AMLO” (32.8%). Un total de 9 etiquetas (6.16%) fueron calificadas como “Ambiguas” pues, al revisar los mensajes parecían usadas de forma indistinta por sendos grupos mientras que 42 (28.7%) no calificaron en ninguna de las categorías.
Distribución de los hashtags utilizados en la conversación por “orientación” ya sea a favor o en contra de Andrés Manuel López Obrador.
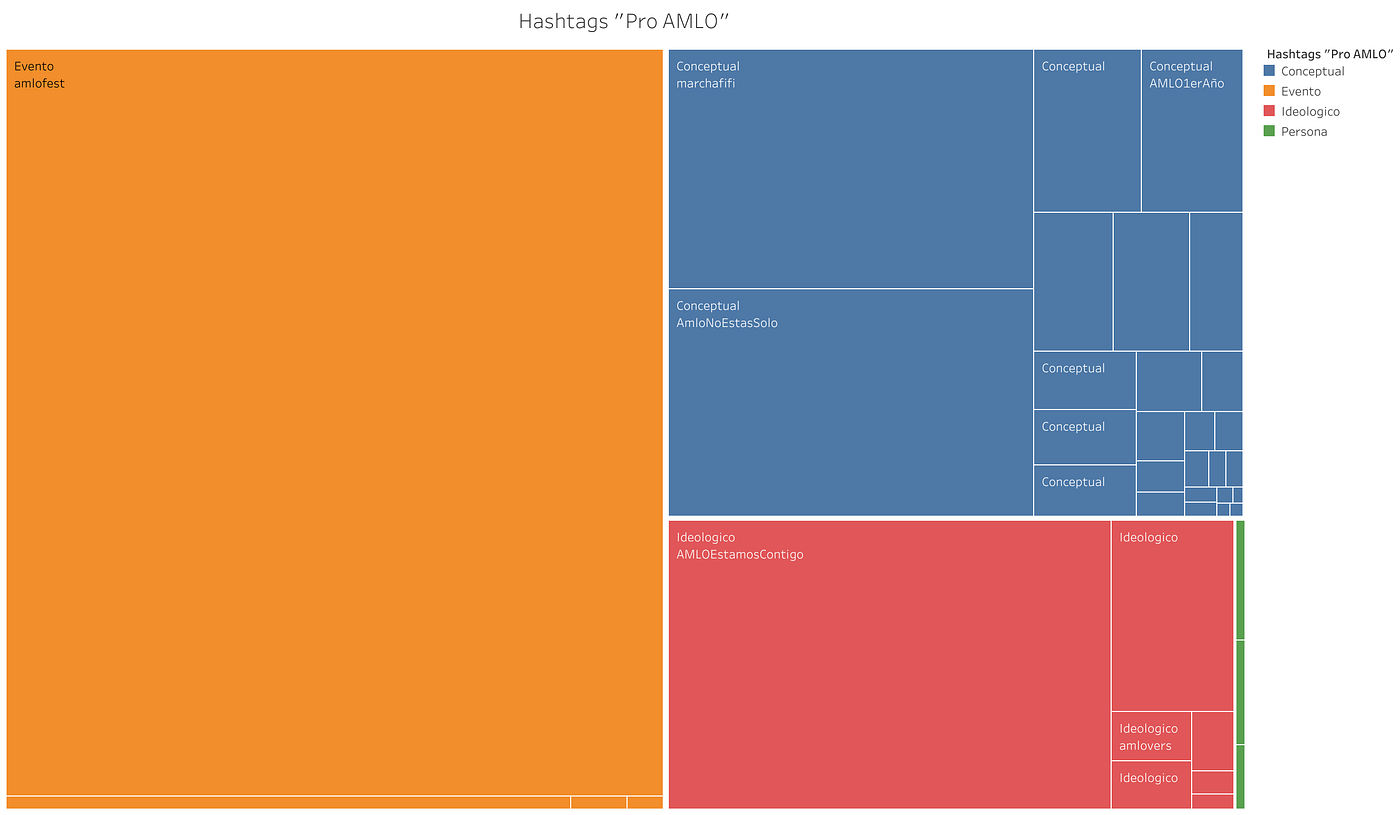
El discurso “Pro AMLO”
La tabla mostrada a continuación muestra la distribución de las etiquetas “Pro AMLO”. Las más utilizadas de las 48 etiquetas fueron las Conceptuales (30 HTs, 62.5% del total de este grupo). El discurso digital del grupo a favor de López Obrador dedica parte de sus esfuerzos hacia la #marchafifí, forma en la que designa a la movilización opositora que se realizó el 1 de diciembre del Ángel de la Independencia al Monumento a la Revolución. Es una etiqueta de directo antagonismo al grupo adversario. Pero le siguen en importancia hastags tales como #AMLONoEstasSolo, #GobiernoDelPueblo y #EsUnHonorEstarConObrador, entre otros. El enmarcamiento que parecen proponer es a la vez de contraposición con el grupo adversario y de unidad en torno a la imagen del presidente de la república. De ahí que otras etiquetas asociadas en esta parte del discurso sean #OposicionMoralmenteDerrotada entre otros.
La identidad del grupo se engloba en torno a etiquetas como #amlovers, #todosalzocaloconAMLO, #AMLOestamoscontigo (esta última, aunque similar a la conceptual #AMLONoEstasSolo, se colocó en este grupo por la definición de la primera persona con la que se construyó la etiqueta).
Distribución y categorías de los hashtags utilizados en la conversación por la red “Pro AMLO”. El tamaño de los recuadros expresa su grado con pesos dentro de la red.
Lo que parece proponer, de manera global, la red “Pro AMLO” es la existencia de un sector que apoya incondicionalmente al personaje político que engloba la discusión. Interpretan y proponen la discusión desde una posición superior a la de la oposición y de cohesión en torno a la imagen de López Obrador.
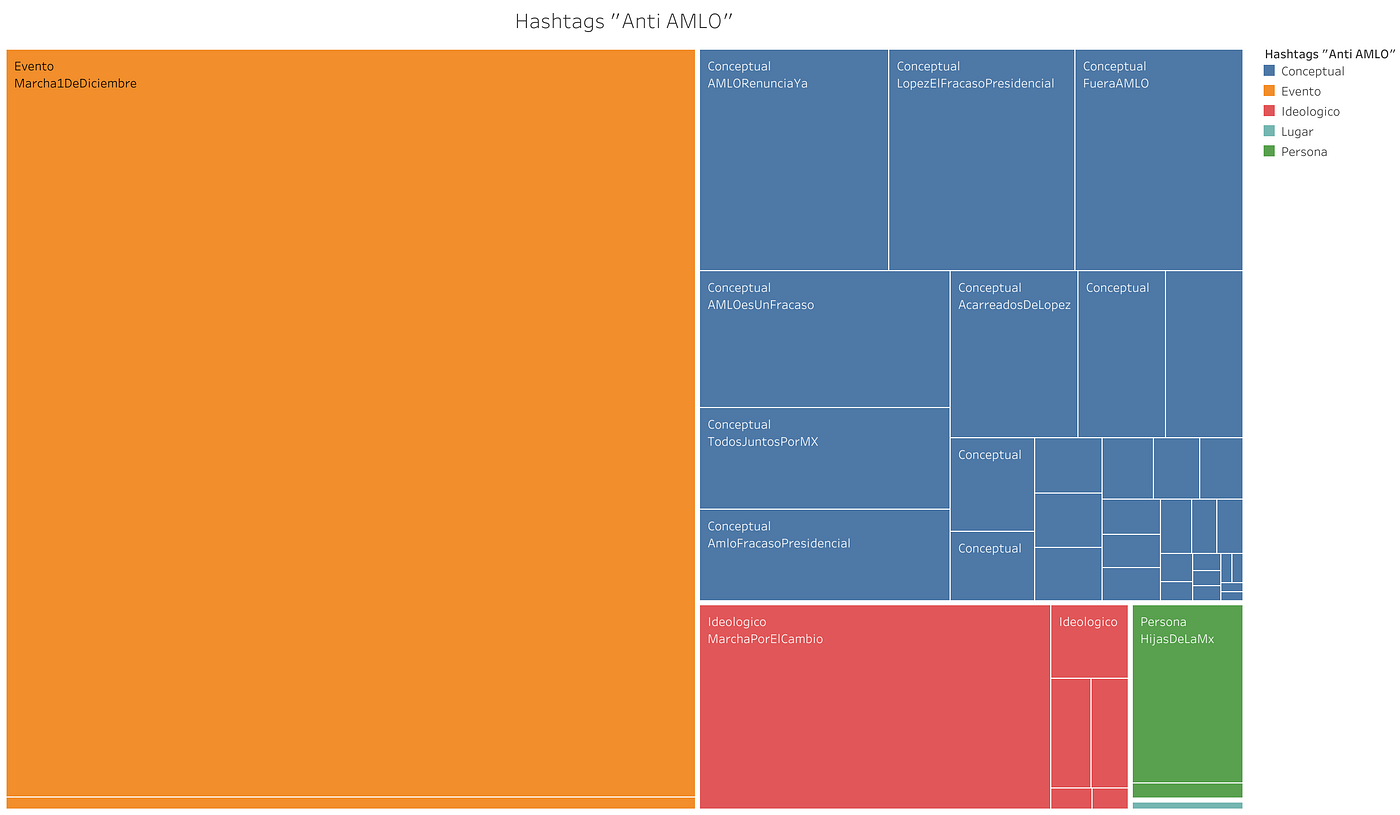
El discurso “Anti AMLO”
La siguiente tabla muestra la distribución de las etiquetas “Anti AMLO”. Las más utilizadas (34 HTs, 72.3% del total del grupo) son de nuevo, Conceptuales. En el discurso digital contra López Obrador aparece como más central #AMLORenunciaYA, acompañada de etiquetas como #LopezElFracasoPresidencial, #FueraAMLO, #AMLOEsUnFracaso, entre otras del mismo tipo. La estrategia de enmarcamiento del grupo opositor parece proponer la desaprobación de la gestión presidencial y la demanda de renuncia del gobierno en curso. Pero también hay etiquetas que buscan oponerse a la otra red, del mismo modo que aquella propuso #marchafifí, en el discurso “Anti AMLO” hay etiquetas como: #AcarreadosDeLopez, #LosDelZocaloSonAcarreados. Sin embargo, el discurso antagónico hacia el otro grupo no es tan central, sino que la desaprobación presidencial es el principal contenido del discurso digital de esta red.
La toma de posición de esta red se engloba en etiquetas como #MarchaPorElCambio y #OposiciónCiuadadana, e incluso #AntiAMLO, entre otras. Lo que esta sección del discurso parece proponer es su diferenciación con el grupo antagónico, pero además, la de una composición ciudadana — que implícitamente sugiere que otros grupos no lo son — bajo la cual se buscaría establecer la legitimidad de la demanda.
Distribución y categorías de los hashtags utilizados en la conversación por la red “Anti AMLO”. El tamaño de los recuadros expresa su grado con pesos dentro de la red.
En resumen, la movilización digital “Anti AMLO” no solo propone desaprobar la gestión de López Obrador sino significar su activación como legítima y ciudadana, un valor que buscarían reivindicar para aumentar la cohesión del grupo.
Activación y diálogo: el intersticio de las redes
Un problema al captar hashtags mediante extracciones de Twitter es que se vuelve difícil “ver” a aquellos usuarios que se han incrustado en el debate sin utilizar las etiquetas.
Mientras que los grupos a favor o en contra de López Obrador, en redes, parecen tener cierta cohesión (si bien pueden ser en parte producto de automatismos, no hay que subestimar la cantidad de usuarios “reales” que participan y se compromete con la discusión), más que diálogo parecen existir dos cajas de resonancia que se aíslan una a la otra, pero que no dejan de dirigirse mensajes, calificaciones y reivindicaciones.
Pero es en el intersticio que se forma entre estas dos esferas donde podría estarse dando el verdadero debate entre usuarios, el verdadero diálogo, si alguno. Quizá uno de los efectos de estas redes de activación digital en torno a las coyunturas políticas, con el uso estratégico de hashtags que tienen, es la invisibilización de los espacios de diálogo que el ambiente digital provee a los usuarios.
En contra de la hipótesis de la polarización (que no está exenta de valiosas interpretaciones del fenómeno), lo que queremos decir con esta respuesta ensayada es que, es posible que uno de los efectos de la disputa por las redes digitales sea la reducción de la densidad o el sometimiento a la gravedad de los hashtags de esos intercambios comunicativos valiosos y que no dejan de presentarse en las redes pero que se vuelven más difíciles de ver cuando el algoritmo nos conduce hacia los mensajes más virulentos a veces, y masivos casi siempre, de las redes antagónicas que se disputan el derecho a designar e interpretar el espacio político digital en el que nos encontramos.
Referencias
Blevins, J. L., Lee, J. J., McCabe, E. E., & Edgerton, E. (2019). Tweeting for social justice in #Ferguson: Affective discourse in Twitter hashtags. New Media & Society, 21(7), 1636–1653. https://doi.org/10.1177/1461444819827030
Treré, E. (2015). Reclaiming, proclaiming, and maintaining collective identity in the #YoSoy132 movement in Mexico: An examination of digital frontstage and backstage activism through social media and instant messaging platforms. Information, Communication & Society, 18(8), 901–915. https://doi.org/10.1080/1369118X.2015.1043744
Xu, S., & Zhou, A. (2020). Hashtag homophily in twitter network: Examining a controversial cause-related marketing campaign. Computers in Human Behavior, 102, 87–96. https://doi.org/10.1016/j.chb.2019.08.006